The output .id column can be used in downstream grouping operations. Default
max_dist = 0 means that both overlapping and book-ended intervals will be
clustered.
Value
ivl_df with .id column specifying sets of clustered intervals.
Details
input tbls are grouped by chrom by default, and additional
groups can be added using dplyr::group_by(). For example,
grouping by strand will constrain analyses to the same strand. To
compare opposing strands across two tbls, strands on the y tbl can
first be inverted using flip_strands().
See also
https://bedtools.readthedocs.io/en/latest/content/tools/cluster.html
Other single set operations:
bed_complement(),
bed_flank(),
bed_genomecov(),
bed_merge(),
bed_partition(),
bed_shift(),
bed_slop()
Examples
x <- tibble::tribble(
~chrom, ~start, ~end,
"chr1", 100, 200,
"chr1", 180, 250,
"chr1", 250, 500,
"chr1", 501, 1000,
"chr2", 1, 100,
"chr2", 150, 200
)
bed_cluster(x)
#> # A tibble: 6 × 4
#> chrom start end .id
#> <chr> <dbl> <dbl> <int>
#> 1 chr1 100 200 1
#> 2 chr1 180 250 1
#> 3 chr1 250 500 1
#> 4 chr1 501 1000 2
#> 5 chr2 1 100 3
#> 6 chr2 150 200 4
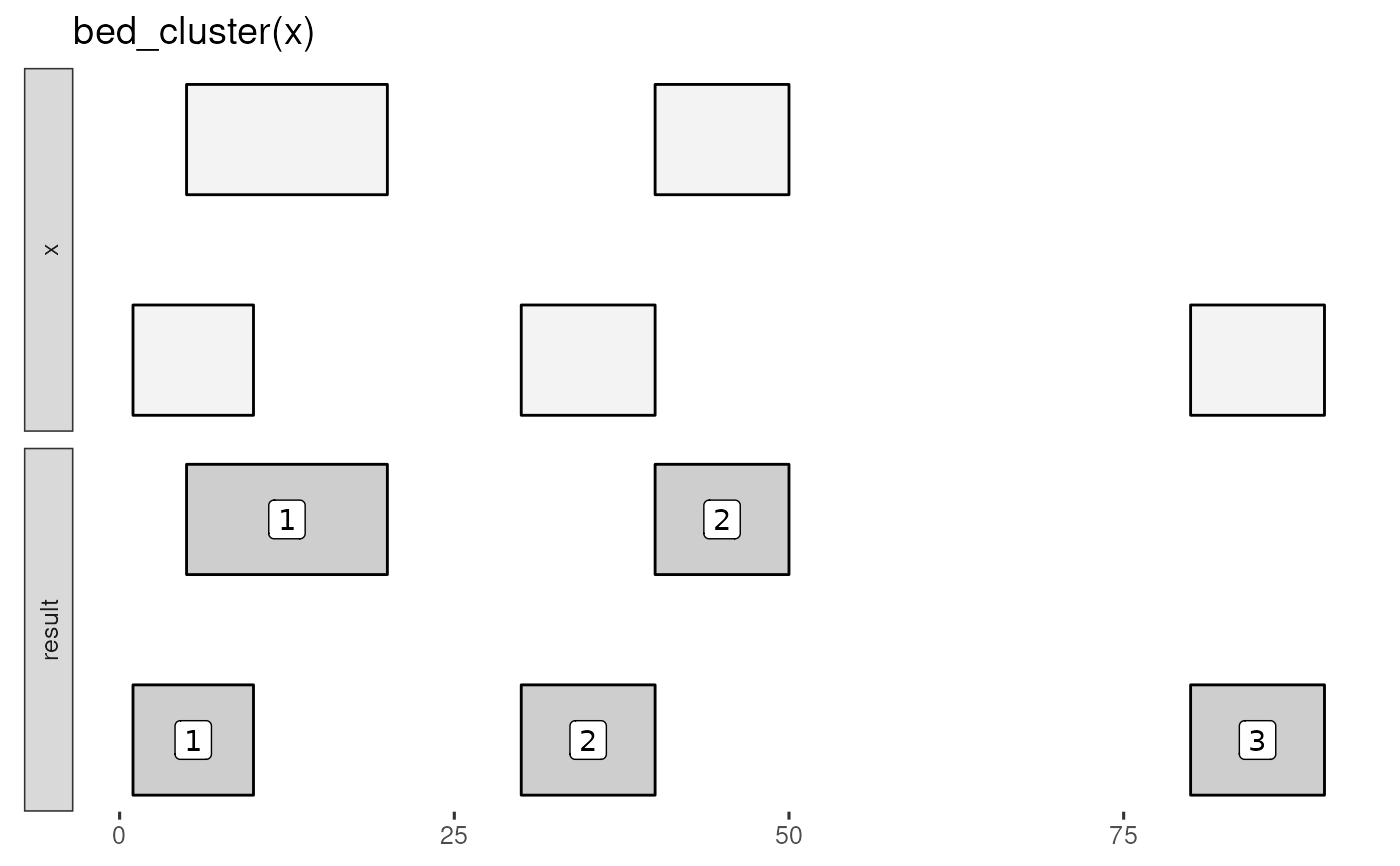
# glyph illustrating clustering of overlapping and book-ended intervals
x <- tibble::tribble(
~chrom, ~start, ~end,
"chr1", 1, 10,
"chr1", 5, 20,
"chr1", 30, 40,
"chr1", 40, 50,
"chr1", 80, 90
)
bed_glyph(bed_cluster(x), label = ".id")