quickCluster(): Crude clustering to group related cells into groups with similar expression profiles
computeSumFactors(): Pool counts across clusters to establish an average cell profile for each cluster. Then use deconvolution to estimate a cell-specific scaling factor for normalization
logNormCounts(): Apply scaling factors (size factors) to counts and log transform with a pseudocount.
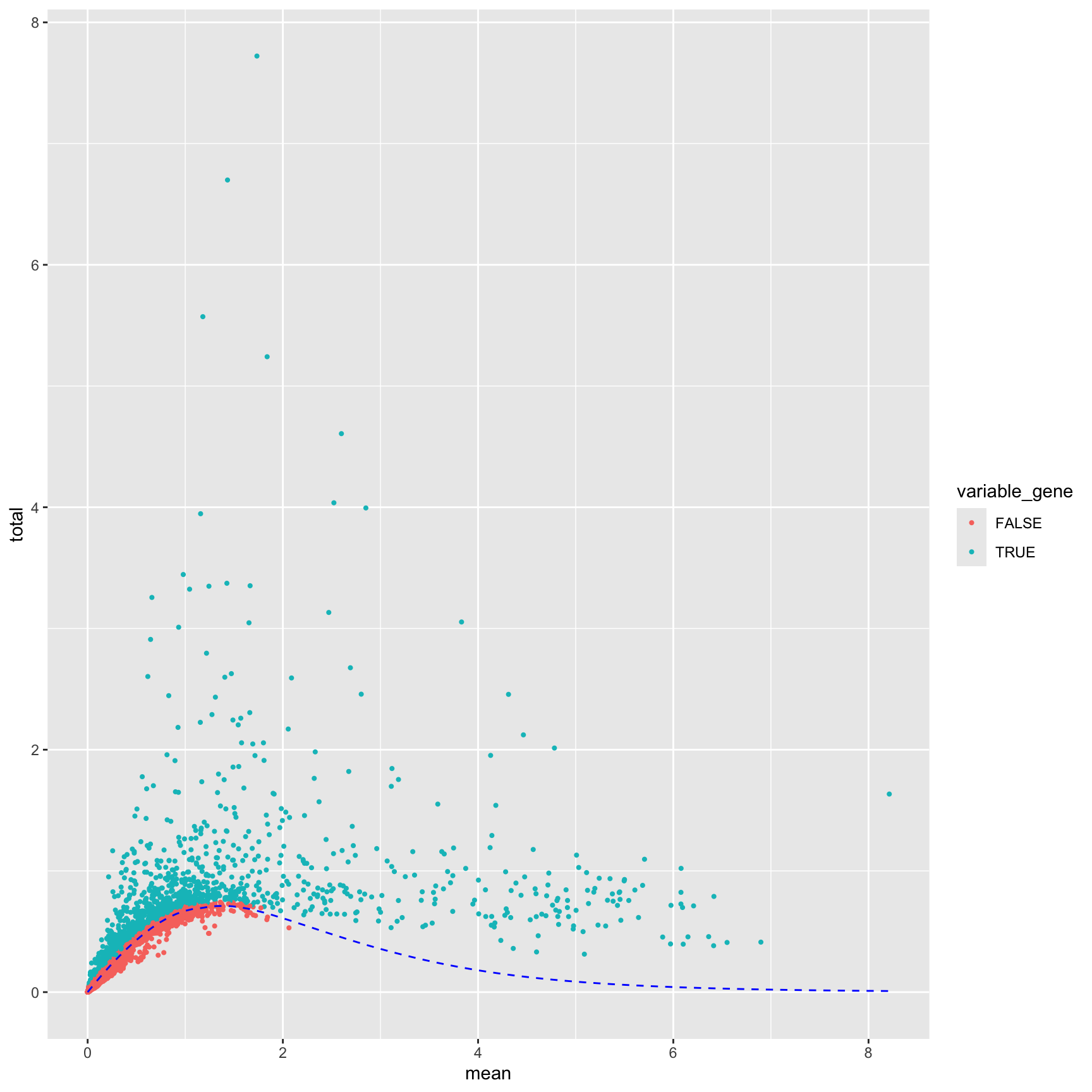
Genes that have high variance across cells are genes that tend to be differentially expressed between cell types
Low variance genes are usually low-expressed or “house-keeping” genes whose expression will not help us distinguish between cell populations
Including these genes could potentially introduce more technical variation rather then helpful biological variation.
Keeping uninteresting genes will increase the computational burden and likely either not improve or be deleterious to the clustering.
Variable gene selection ⌨️
modelGeneVarByPoisson(): Fit curve, using Poisson distribution, to variance against the mean expression distribution. Estimate technical (Poisson estimate) and biological (the residuals from the Poisson) variance for each gene.
getTopHVGs(): Filter output from modelGeneVarByPoisson to select top variable genes. Use prop to identify the proportion of genes to call highly variable or n to identify a number. Often starting between 1000-2000 is best.
?getTopHVGs
Variable gene selection ⌨️
modelGeneVarByPoisson(): Fit curve, using Poisson distribution, to variance against the mean expression distribution. Estimate technical (Poisson estimate) and biological (the residuals from the Poisson) variance for each gene.
getTopHVGs(): Filter output from modelGeneVarByPoisson to select top variable genes. Use prop to identify the proportion of genes to call highly variable or n to identify a number. Often starting between 1000-2000 is best.
set.seed(42)dec <-modelGeneVarByPoisson(sce)
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
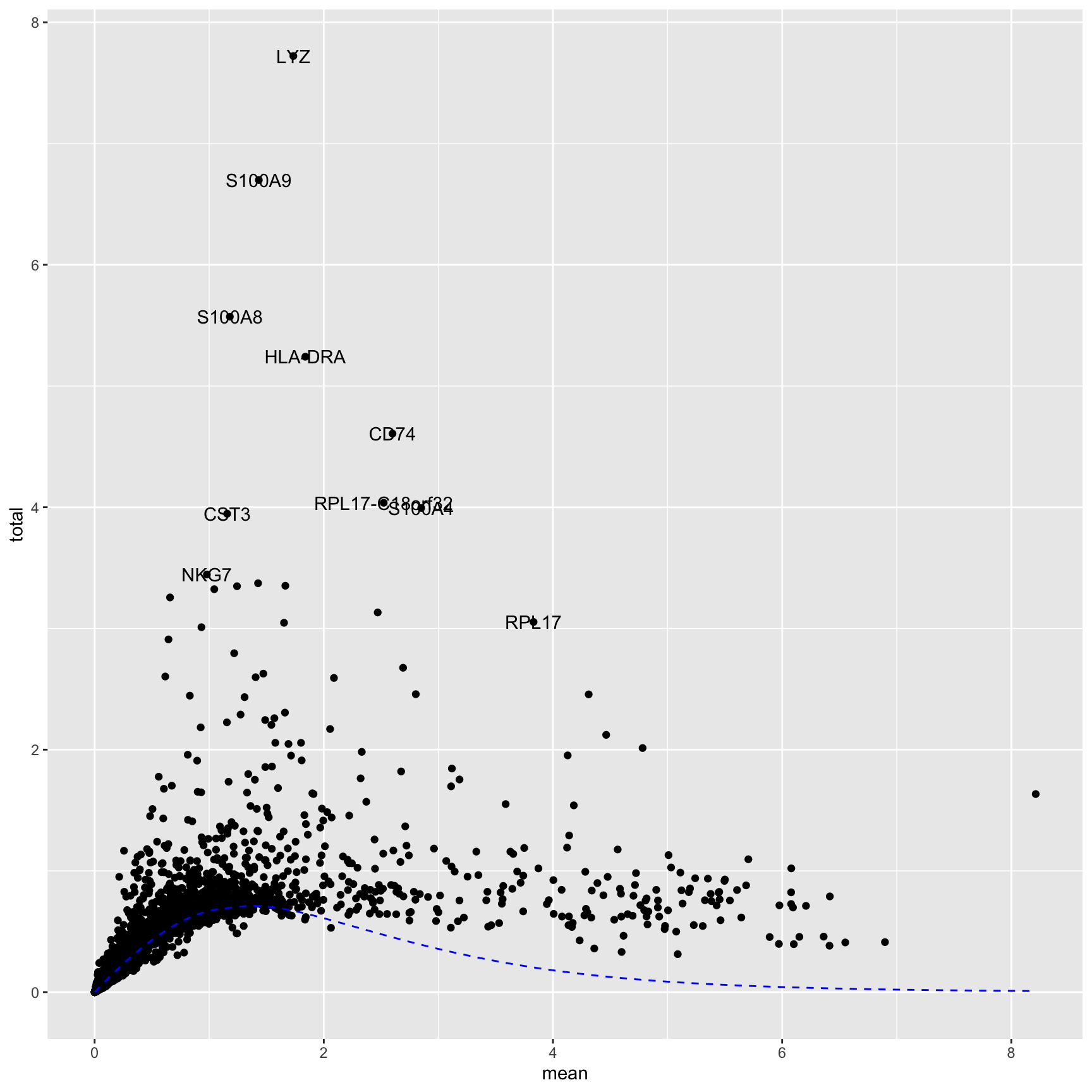
top <-getTopHVGs(dec, prop =0.1)top[1:4]
[1] "LYZ" "S100A9" "S100A8" "HLA-DRA"
Variable gene selection ⌨️
We can plot mean expression against variance to see the trend and visualize the top variable genes. These are often marker genes of specific cell populations.
Dimensionality reduction is the concept of transforming high dimensional data and representing it with a smaller set of dimensions.
We can reduce the # of dimensions without loosing much information because many features (genes) are highly correlated which can be approximated with fewer dimensions.
This is analogous to reducing the gene expression data into a set of metagenes that represents the expression of many correlated genes.
Using fewer dimensions makes computation much quicker and as we will see will reorder the data in a manner that still captures the heterogeneity in the data.
Dimensionality reduction via PCA
We will use PCA to reduce the dimensionality of the data from 20,000 genes to ~10-50 principle components.
PCA takes a matrix of features (genes) and samples (cells) and transforms the matrix into a new set of features known as a principal components. A principal component is a linear combination of the original genes that is oriented to capture variance in the dataset.
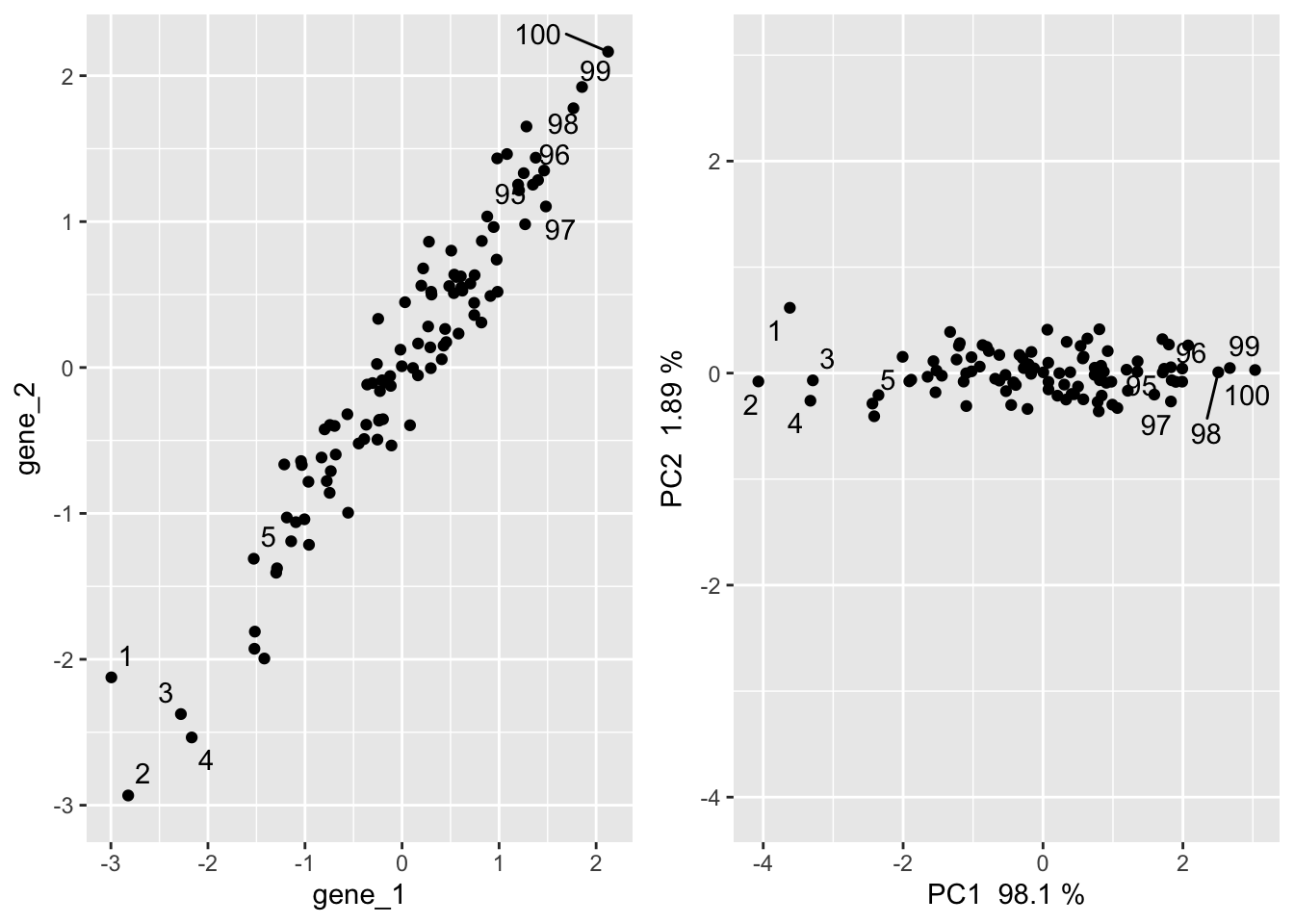
PC1 is a vector through the dataset oriented in a direction that spans the most variation in the data. The second component is another linear combination of the original variables but is uncorrelated to the first component (points in an orthogonal direction).
In a geometric sense, PCA produces a new coordinate system whereby instead of the axes being each gene, the axes are each a PC and the first axis points through the largest spread in the data.
PCA in 2 dimensions
In this two dimensional space, PCA minimizes the distances from a line and every point in the x and y direction (think of a regression line). For a great walk through of how PCA works, see section 7.3 in Modern Statistics for Modern Biology
PCA with more dimensions
If we add more dimensions, we now need to fit this line in a much higher dimensional space while still minimizing the distance of each point from the line.
We end up with the same number of PCs as the number of our initial dimensions
In our 2-D example, we get two PCs
Adding more genes increases the number of PCs.
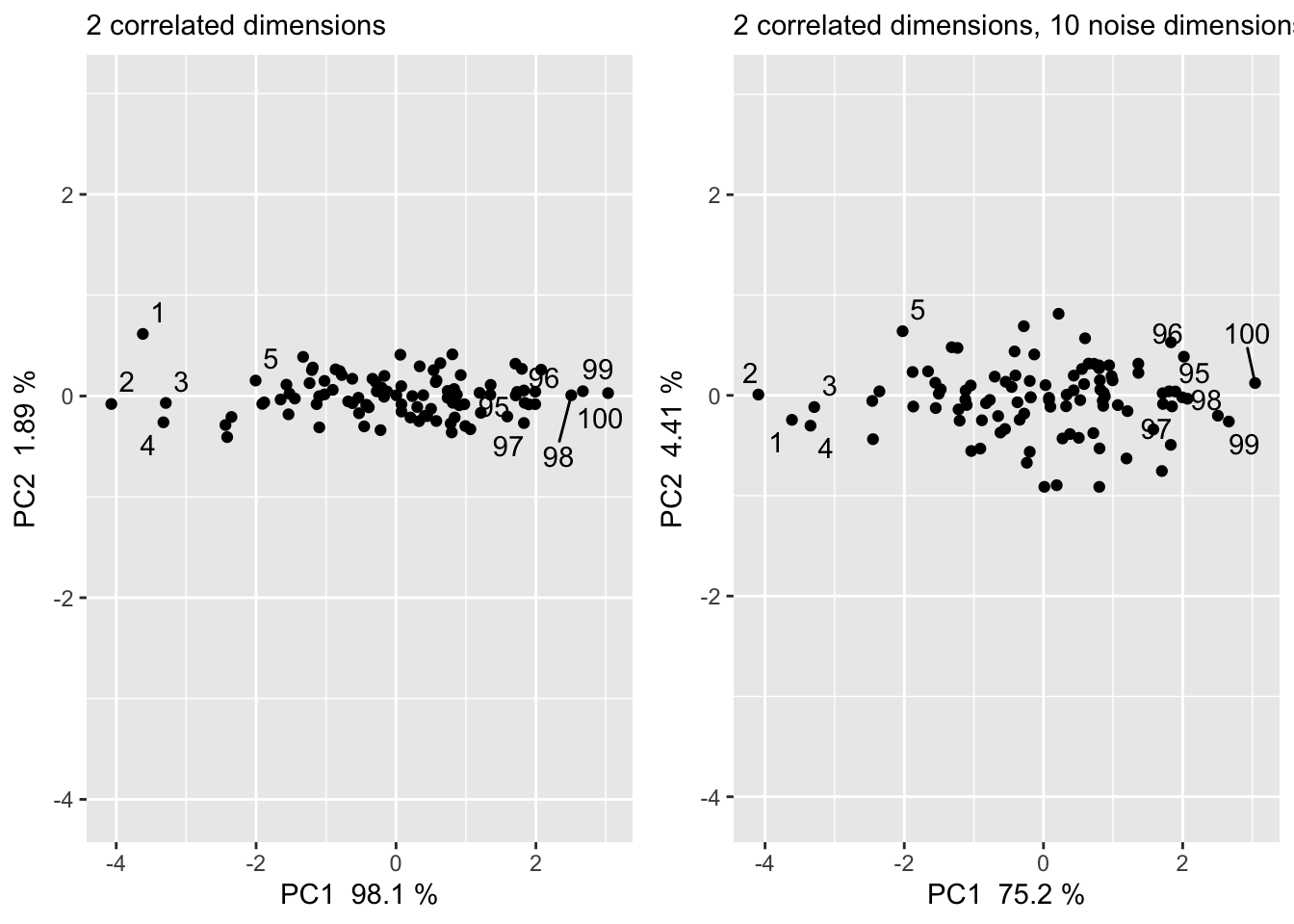
What if we had more dimensions that are uninteresting variance/noise? How does this impact the PCA?
PC 1 and PC 2 capture less of the total variance (from capturing 100% of the variance to capturing about 80% of the variance)
Additionally, the points are spread more and differently because the distance had to be minimized in a higher dimensional space
However adding random noise does not dramatically change PC1 and PC2
computing PCA with scater ⌨️
runPCA(): computes an approximate truncated PCA, returning 50 PCs by default.
reducedDim(sce, "PCA"): function to access or assign reduced dimensionality results
plotPCA(): plot 2 or more PC components
plotReducedDim(): plot 2 or more dimensions or arbitrary reducedDim() matrix
set.seed(101010011) # runPCA uses a specialize form of PCA that has a random componentsce <-runPCA(sce, subset_row = top)
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
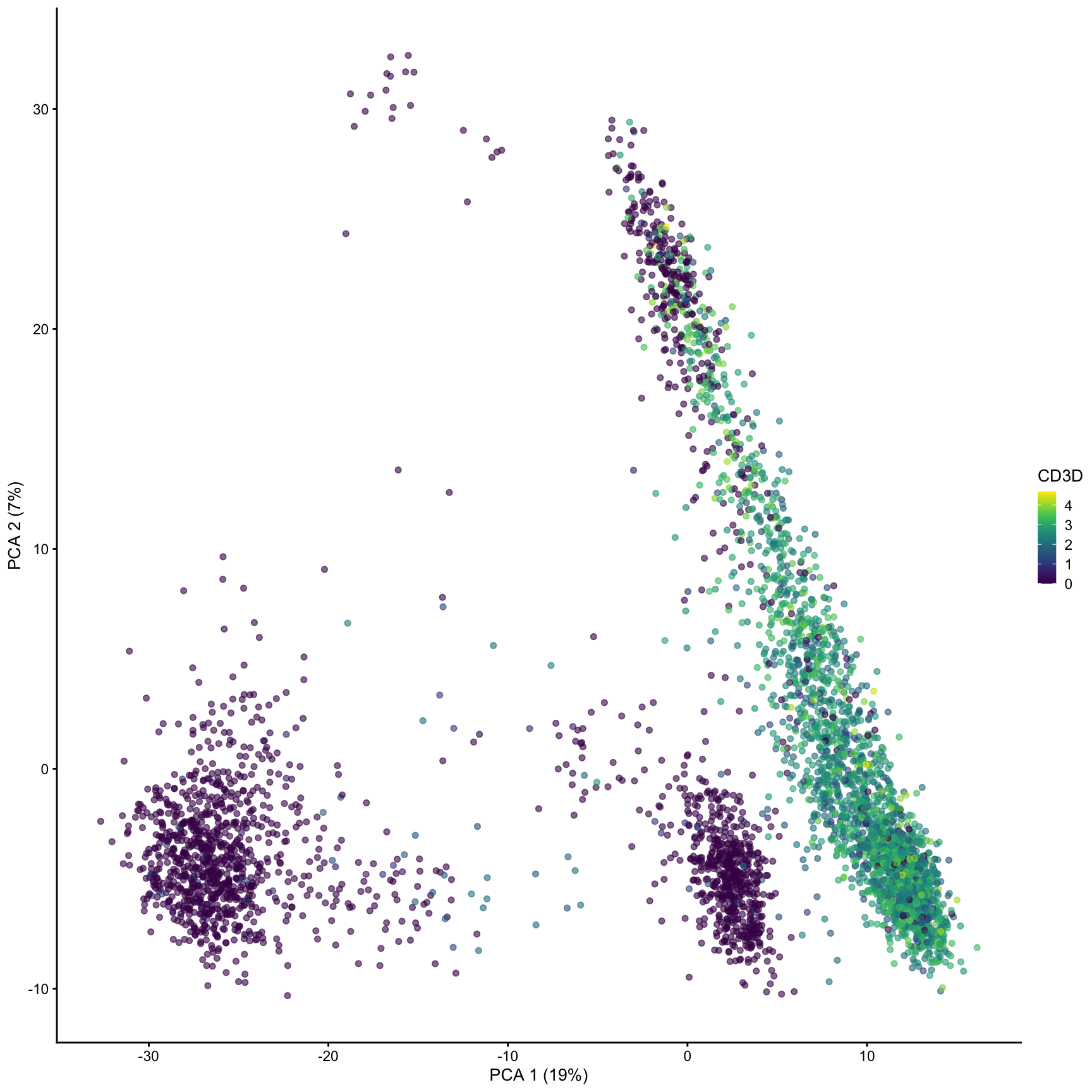
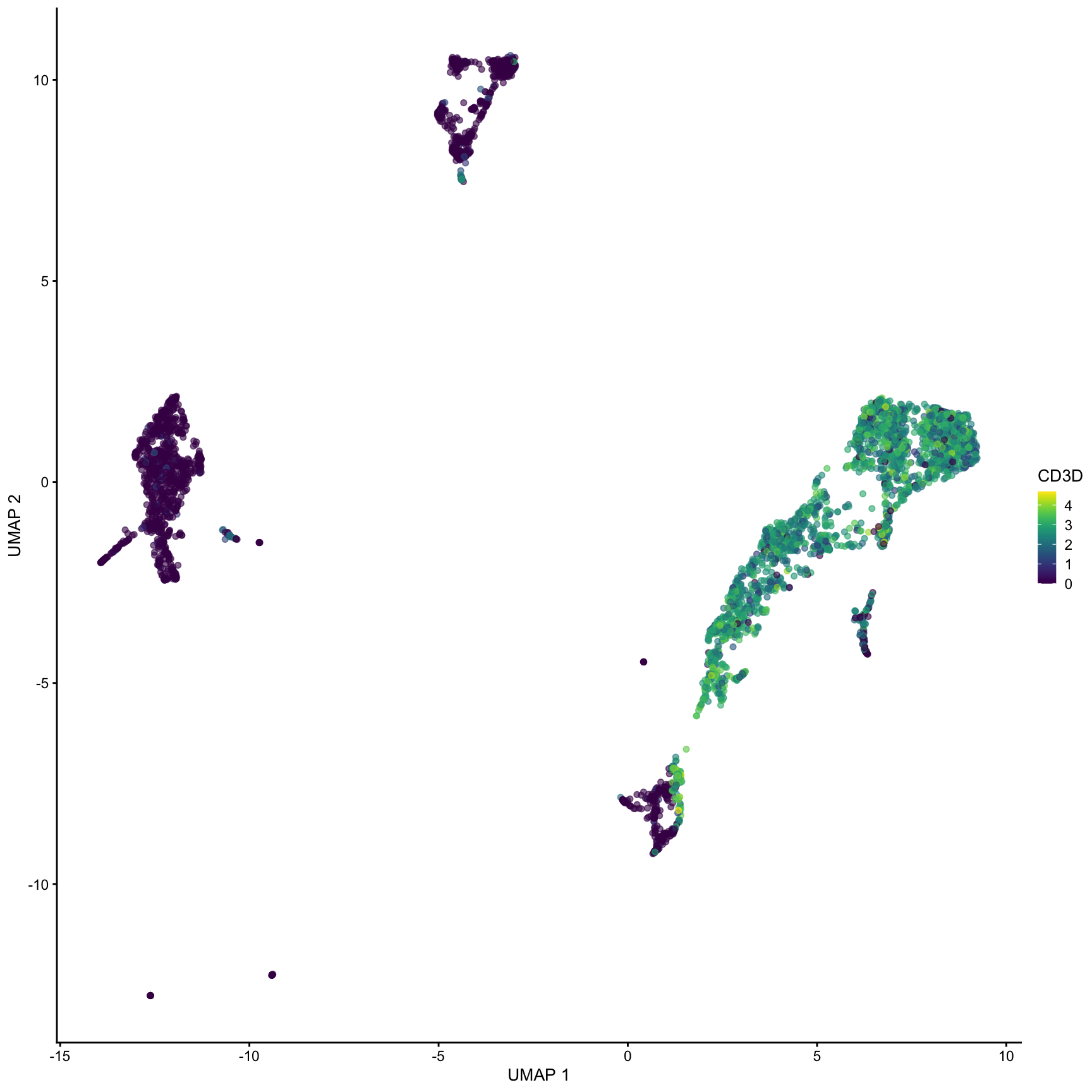
plotPCA(sce, color_by ="CD3D")
computing PCA with scater ⌨️
runPCA(): computes an approximate truncated PCA, returning 50 PCs by default.
reducedDim(sce, "PCA"): function to access or assign reduced dimensionality results
plotPCA(): plot 2 or more PC components
plotReducedDim(): plot 2 or more dimensions or arbitrary reducedDim() matrix
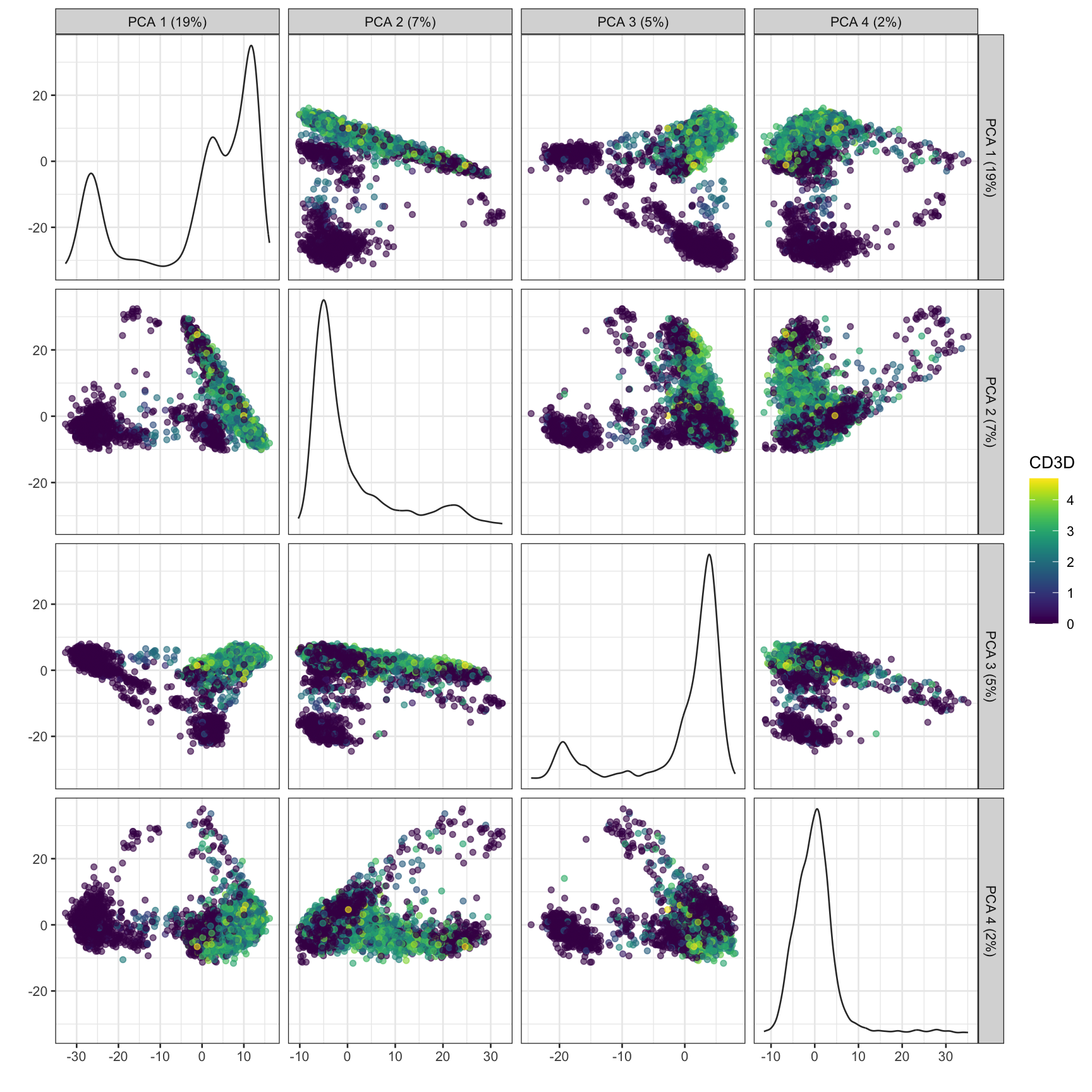
plotPCA(sce, ncomponents =4, colour_by ="CD3D")
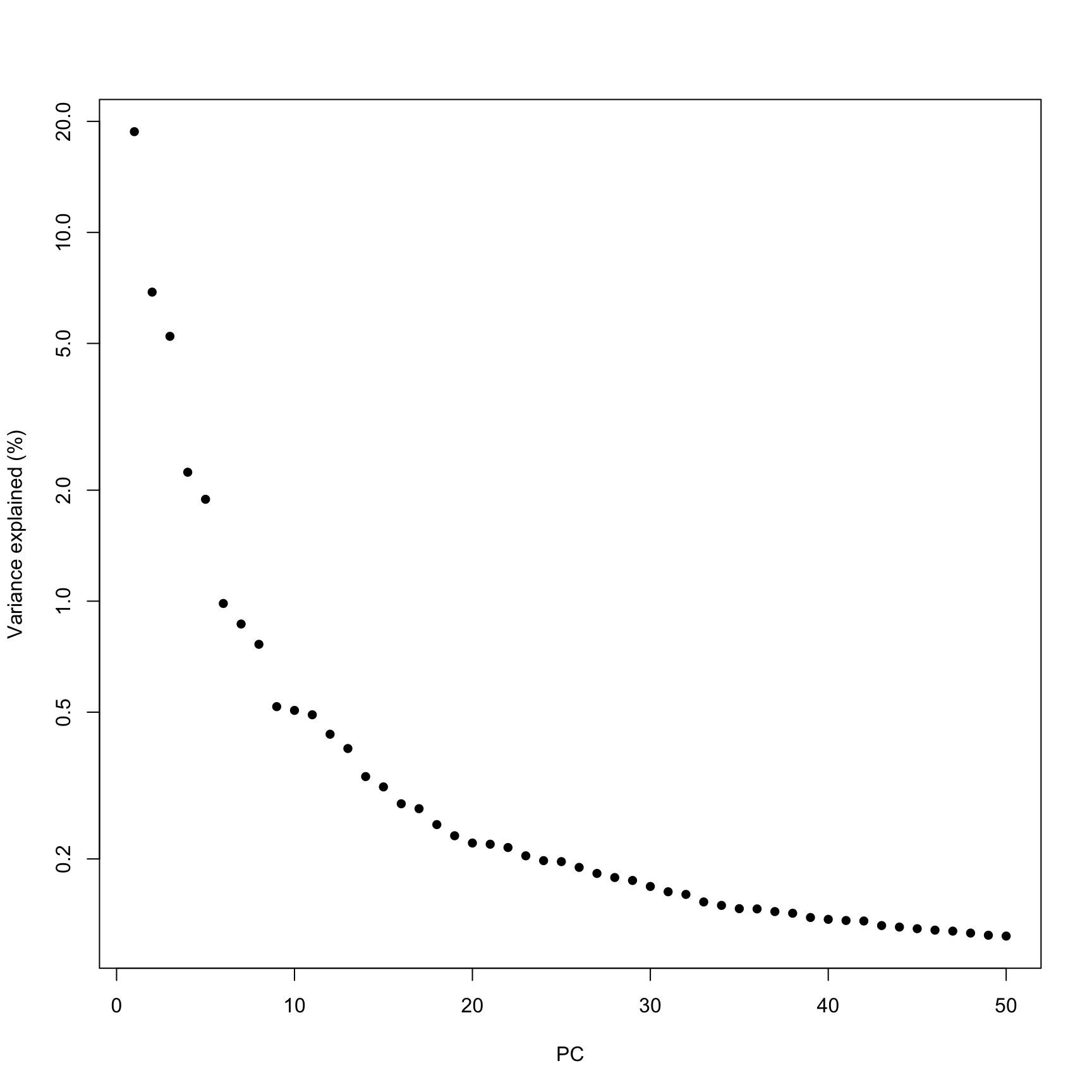
How many PCs to retain? ⌨️
In general the # of PCs to use for downstream steps depends on the complexity and heterogeneity in the data, as well as the biological question. For this analysis we will retain the top 30, but you should explore how the downstream steps are affected by including fewer or more PCs.
In practice picking fewer PCs will identify fewer subpopulations, and picking more PCs will find more subpopulations, at the expense of potentially increased noise and longer runtime.
We use clustering to assign cells to discrete cell populations. This is a simplification of the true complexity of the underlying data.
Clustering is a data analysis tool rather than a result. We can increase, decrease, merge, or subset clusters at our whim by changing clustering parameters, the # of PCs used, the # of variable genes, and the particular cell subsets analyzed.
There is no correct or valid number of clusters. It depends on what biological question you are trying to explore and at what granularity you want to ask the question.
[A]sking for an unqualified “best” clustering is akin to asking for the best magnification on a microscope without any context - OSCA book
Graph based clustering
Approach:
identify the K nearest neighbors of each cell in the PCA matrix (e.g. k = 10)
weight the connection between cells based on “connectivity” of shared nearest neighbors (total number, proportion, average rank of neighbors, etc.)
apply a community detection algorithm to cluster the shared nearest neighbor graph (walktrap, louvain, leiden, etc.)
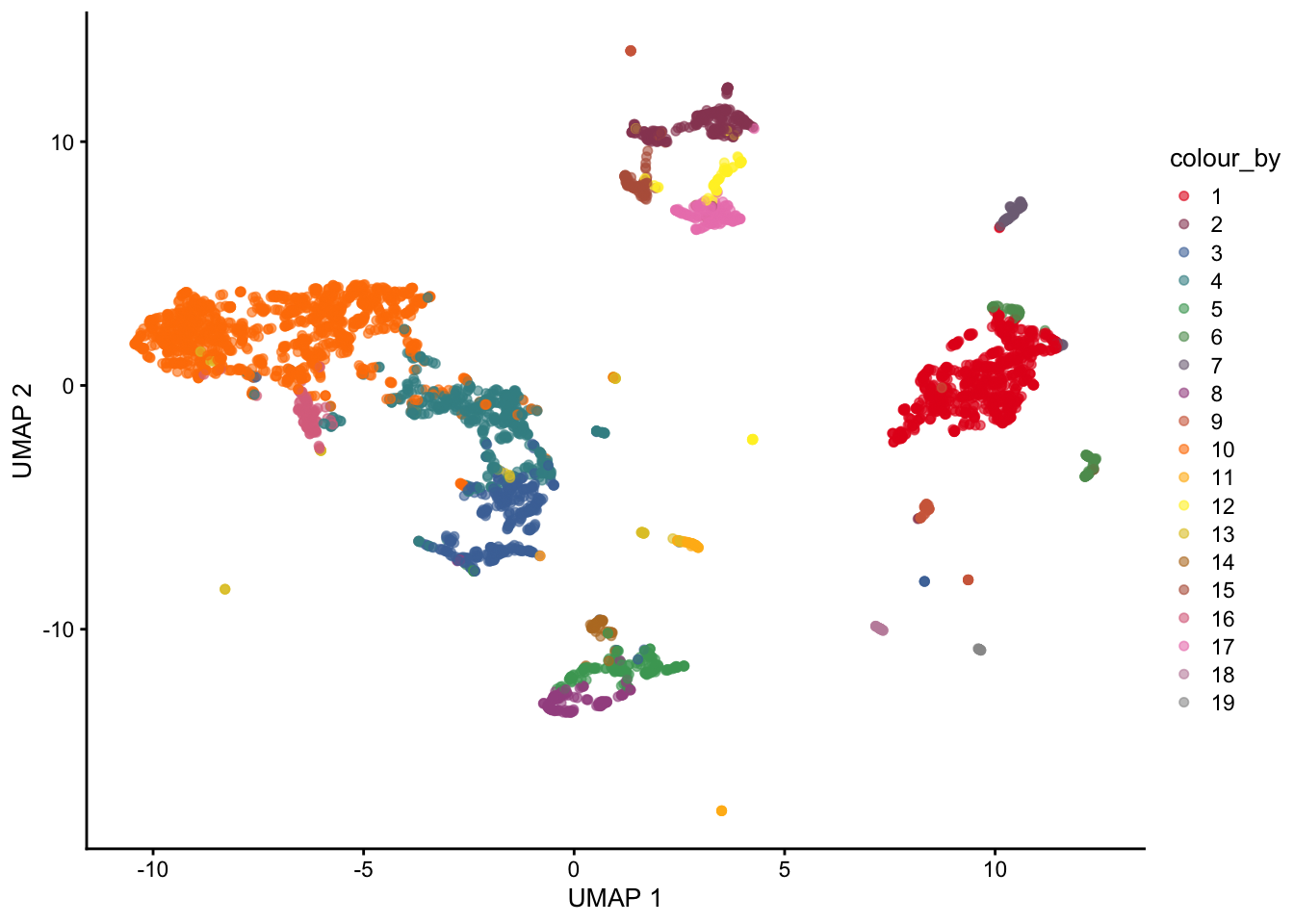
clusterCells()
Clustering ⌨️
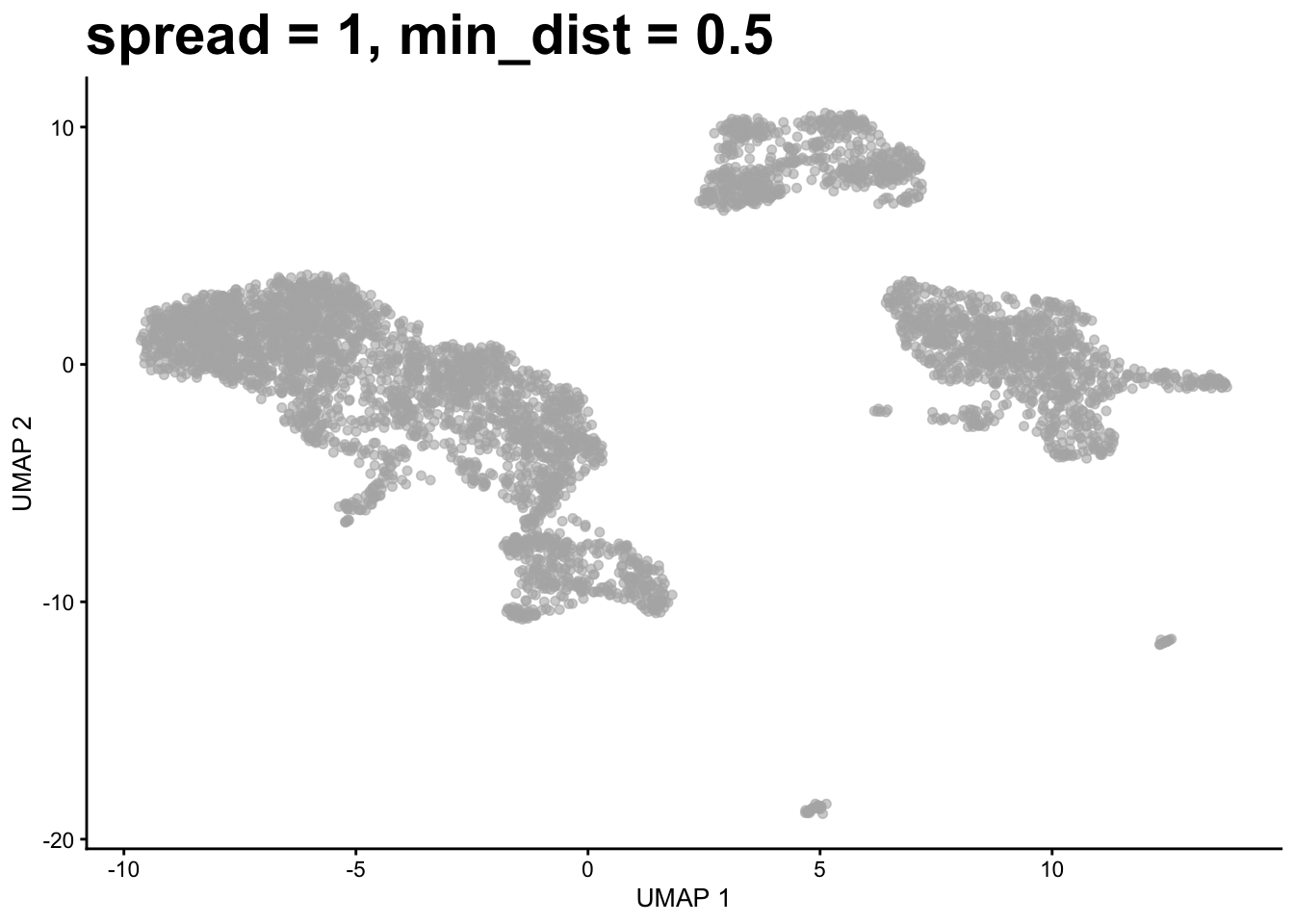
Note that the clustering is performed on the PCA matrix not the 2D UMAP plot
Scale for colour is already present.
Adding another scale for colour, which will replace the
existing scale.
Clustering ⌨️
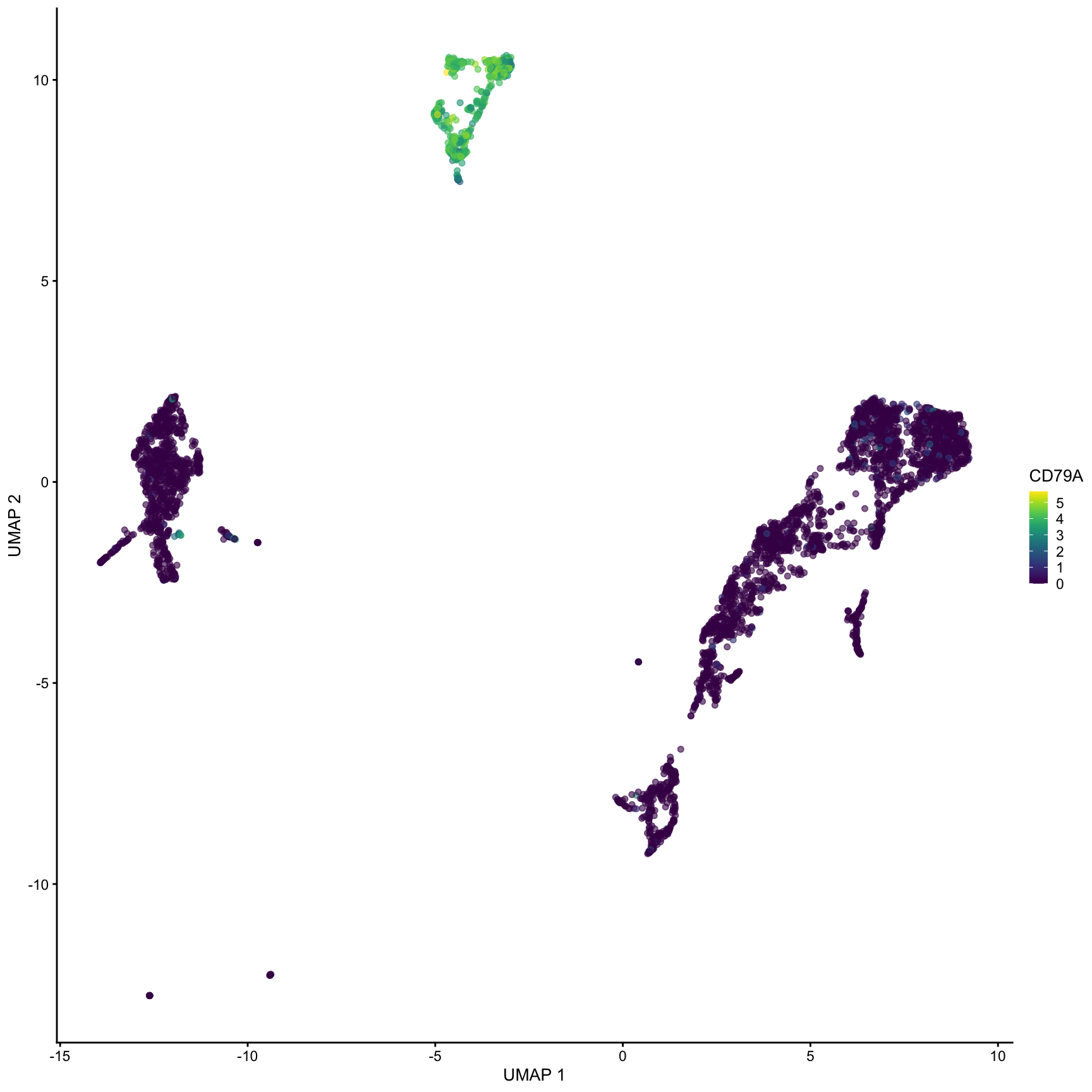
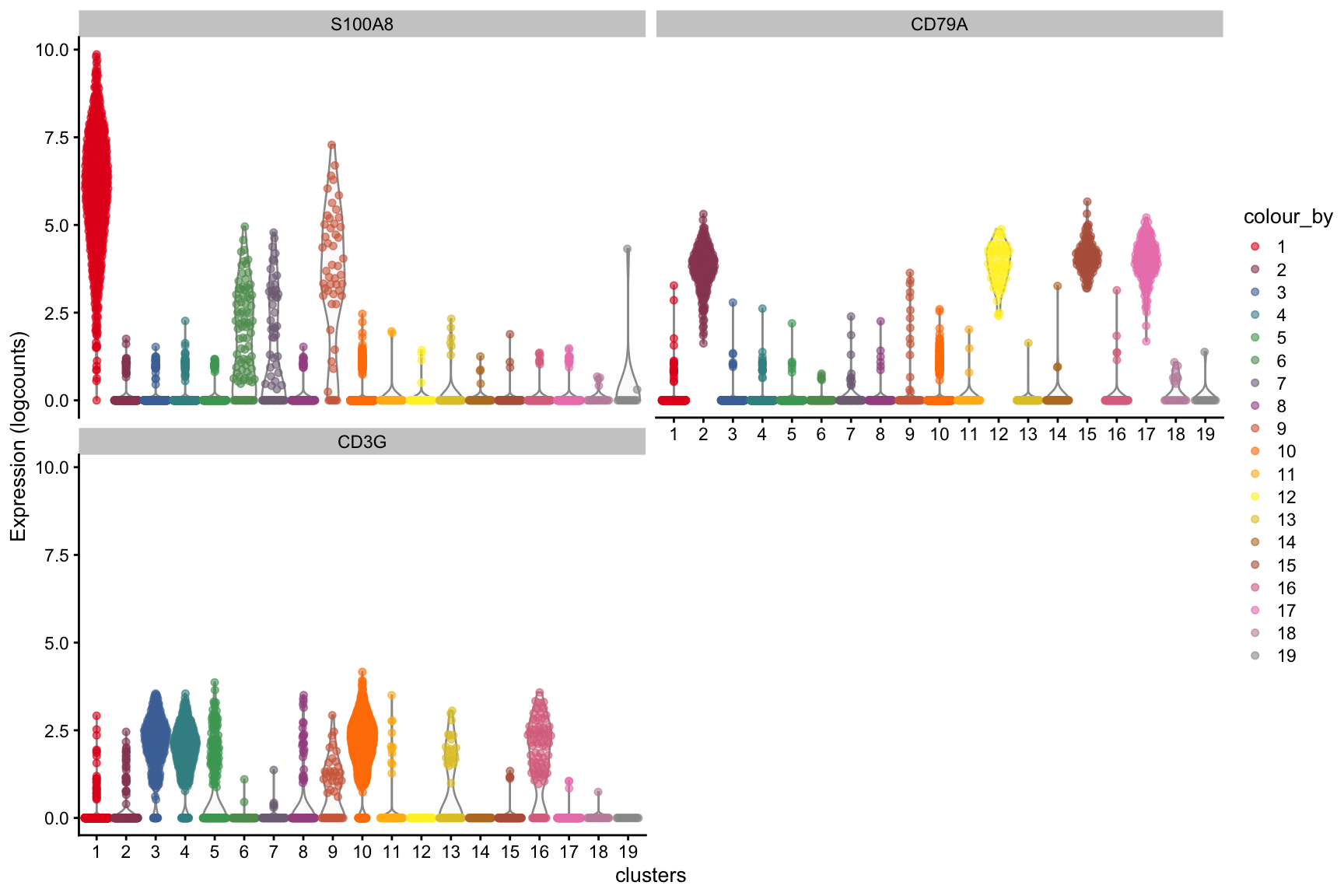
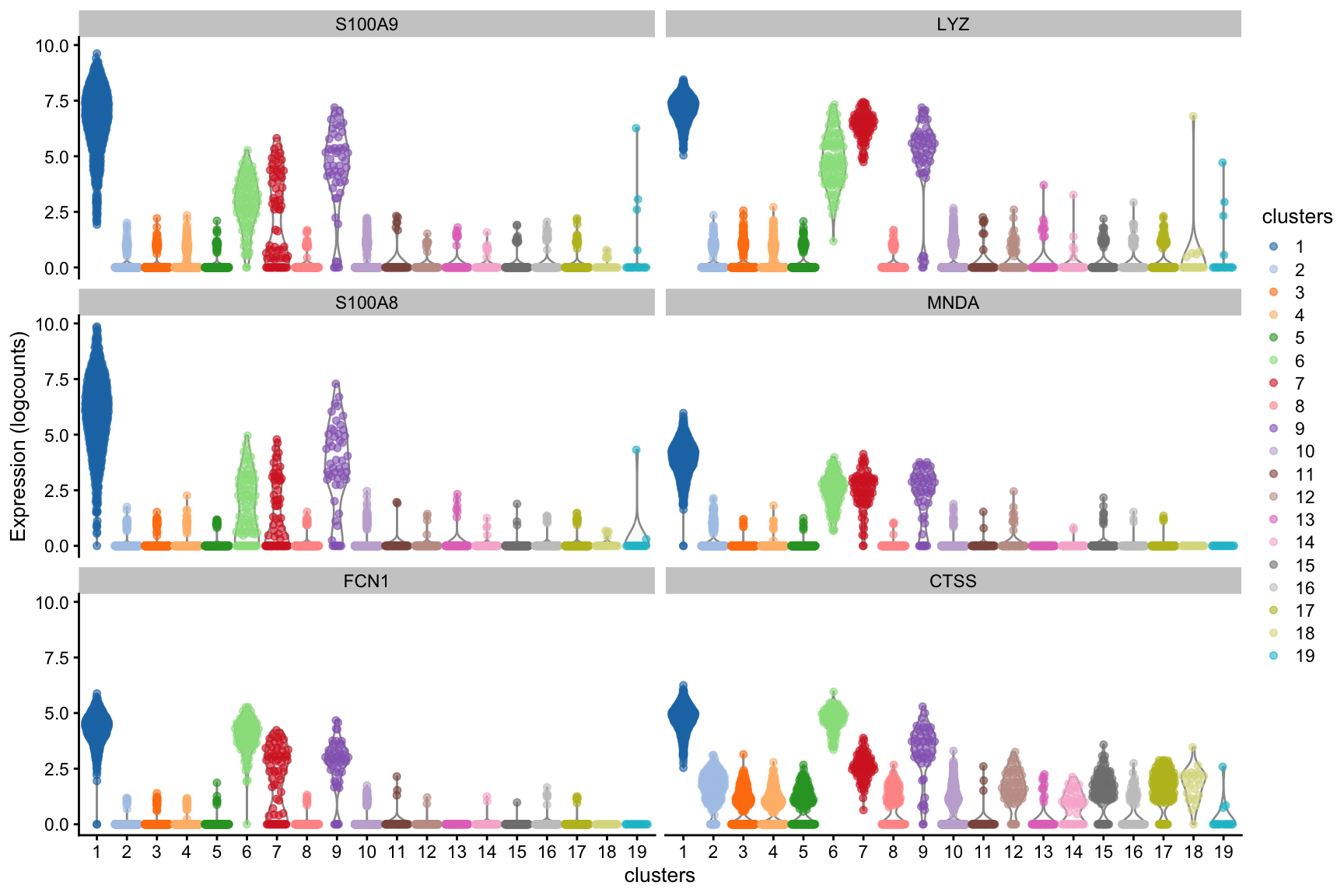
What clusters are the genes S100A8, CD79A and CD3G most highly expressed in? We can use the plotExpression() function to visualize the expression data in each cluster.
Scale for colour is already present.
Adding another scale for colour, which will replace the
existing scale.
How many clusters?
Clustering algorithms produce clusters, even if there isn’t anything meaningfully different between cells. Determining the optimal number of clusters can be tricky and also dependent on the biological question.
Some guidelines:
Cluster the data into a small number of clusters to identify cell types, then recluster to generate additional clusters to define sub-populations of cell types.
To determine if the data is overclustered examine differentially expressed genes between clusters. If the clusters have few or no differentially expressed genes then the data is likely overclustered. Similar clusters can be merged post-hoc if necessary as sometimes it is difficult to use 1 clustering approach for many diverse cell populations. Using a reference-based approach to name cell types will also often merge similar clusters.
A hybrid approach is to first annotate major cell types using a small # of clusters (e.g. B-cell, T-cell, Myeloid, etc.), then subset the SingleCellExperiment object for each cluster and perform additional clustering to obtain ‘subclusters’ (e.g. b-cell-subset 1, b-cell-subset 2, t-cell-subset-1, etc.)
Identifying marker genes using scoreMarkers()
Clustering algorithms produce clusters, even if there isn’t anything meaningfully different between cells. Determining the optimal number of clusters can be tricky and also dependent on the biological question.
Some guidelines:
Cluster the data into a small number of clusters to identify cell types, then recluster to generate additional clusters to define sub-populations of cell types.
To determine if the data is overclustered examine differentially expressed genes between clusters. If the clusters have few or no differentially expressed genes then the data is likely overclustered. Similar clusters can be merged post-hoc if necessary as sometimes it is difficult to use 1 clustering approach for many diverse cell populations. Using a reference-based approach to name cell types will also often merge similar clusters.
A hybrid approach is to first annotate major cell types using a small # of clusters (e.g. B-cell, T-cell, Myeloid, etc.), then subset the SingleCellExperiment object for each cluster and perform additional clustering to obtain ‘subclusters’ (e.g. b-cell-subset 1, b-cell-subset 2, t-cell-subset-1, etc.)
Identifying marker genes using scoreMarkers() ⌨️
mrks <-scoreMarkers(sce, sce$clusters)
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
Warning in .pause_resource(): omp_pause_resource() failed to relinquish resources on
device 0
What is a marker gene? * Differentially expressed between cluster 1 and all others? * This could be too strict, what if the same gene marks clusters 1-8 but not 9? We would miss that as a marker * Differentially expressed between some or any pairwise clusters
The output of scoreMarkers() allows you to filter the data in many different ways depending on what type of marker you want to identify. Importantly it doesn’t hide the complexity of this data. I highly recommend reading the chapter on marker gene detection from the OSCA book to understand how best to identify markers depending on the dataset you are analyzing.
How do we identify marker genes?
We will use AUC to rank markers
Probability that a randomly chosen observation from our cluster of interest is greater than a randomly chosen obsevation from the other cluster
Value of 1 = upregulated in the cluster of interest, 0 = downregulated, 0.5 = no difference.
Other ranking options include log fold change or fold change in the detection rate
Can chose mean, min, median, max, or rank for potential ranking
Paraphrasing from the OSCA book: * The most obvious summary statistic is the mean. For cluster X, a large mean effect size (>0.5 for the AUCs) indicates that the gene is upregulated in X compared to the average of the other groups. * Another summary statistic is the median, where a large value indicates that the gene is upregulated in X compared to most (>50%) other clusters. * The minimum value (min.) is the most stringent summary for identifying upregulated genes, as a large value indicates that the gene is upregulated in X compared to all other clusters. The maximum value (max.) is the least stringent summary for identifying upregulated genes, as a large value can be obtained if there is strong upregulation in X compared to any other cluster. The minimum rank, a.k.a., “min-rank” (rank.*) is the smallest rank of each gene across all pairwise comparisons. Specifically, genes are ranked within each pairwise comparison based on decreasing effect size, and then the smallest rank across all comparisons is reported for each gene. If a gene has a small min-rank, we can conclude that it is one of the top upregulated genes in at least one comparison of X to another cluster.
Cluster 1 genes ⌨️
Plotting top genes ranked by mean.AUC for cluster 1.
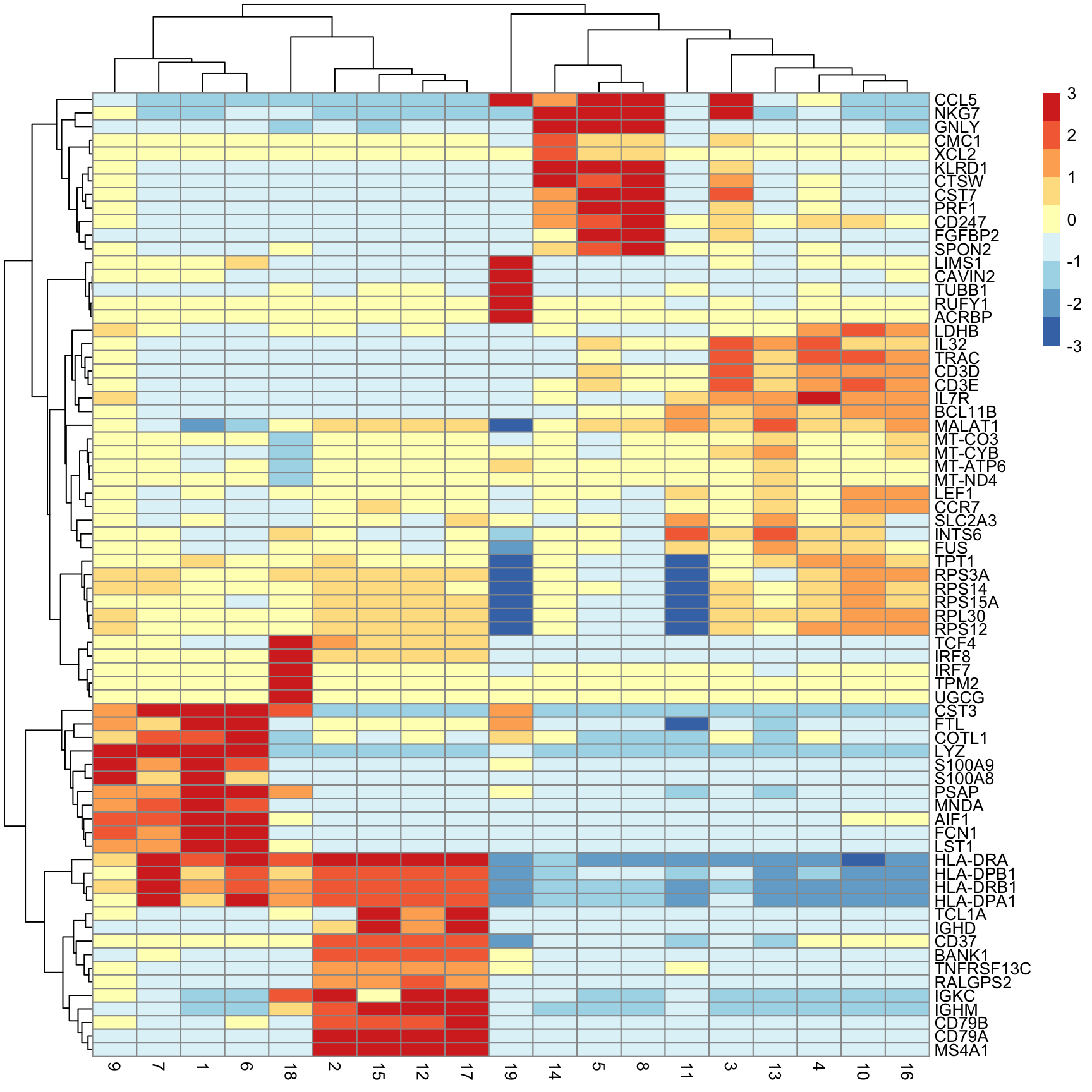
Next we will extract the top N markers from each cluster, ranked on mean.AUC, then plot the average expression of these markers in each cluster as a heatmap.
Next we will extract the top N markers from each cluster, ranked on mean.AUC, then plot the average expression of these markers in each cluster as a heatmap.
Early days of single cell used manual cluster annotation
Using visual inspection of key genes using expertise in the lab
Now it is becomming more comon to compare your dataset to another dataset or a reference
Leads to more reproducability and agreement across publications
Not biased to only a handful of genes, instead thousand of genes are used
Correlation and machine learning approaches are common
Packages include clustifyr, SingleR, SignacX, and Azimuth
Annotating cell types
We we use clustifyr which was developed by a previous RBI fellow Rui Fu. There are also many other methods (e.g. SingleR)
clustifyr compares the average gene expression in each cluster to a reference matrix that contains average gene signatures of reference cell types.
The reference can be built from other single cell data, bulk-rna-seq, or other sources.
Ranked spearman correlation is used to compare the reference to the clusters.
Only the variable genes are used for the correlation.
Fewer variable genes (ie 1000) are recommended as too many genes leads to high correlations across the board (think of a lot of zero values).
In order to compare our dataset we need to use a publicly available reference dataset. Thankfully many datasets have been organized into a separate package: clustifyrdatahub. This is an extension of the ExperimentHub package on bioconductor that allows you to easily download and cache external datasets.
Annotating cell types ⌨️
library(clustifyr)library(clustifyrdatahub)# get reference dataset derived from a microarray experiment of sorted immune cell typesref_hema_microarray()[1:5, 1:5]
res <-clustify( sce, # SingleCellExperiment objectref_mat =ref_hema_microarray(), # cell type reference datacluster_col ="clusters", # column in metadata with clusters# don't add to SingleCellExperiment object, just return resultsobj_out =FALSE,# use variable genes for comparisonquery_genes = top,)
object data retrieval complete, moving to similarity computation
see ?clustifyrdatahub and browseVignettes('clustifyrdatahub') for documentation
loading from cache
using # of genes: 1073
similarity computation completed, matrix of 19 x 38, preparing output
res[1:12, 1:4]
Basophils CD4+ Central Memory CD4+ Effector Memory
1 NA NA NA
10 NA NA NA
11 NA NA NA
12 NA NA NA
13 NA NA NA
14 NA NA NA
15 NA NA NA
16 NA NA NA
17 NA NA NA
18 NA NA NA
19 NA NA NA
2 NA NA NA
CD8+ Central Memory
1 NA
10 NA
11 NA
12 NA
13 NA
14 NA
15 NA
16 NA
17 NA
18 NA
19 NA
2 NA
We can use cor_to_call to pull out the highest correlation for each cluster
cor_to_call(res) # assign cluster to highest correlation cell type (above a threshold). Cell types lower than a threshold will be assigned as unassigned.
Annotating cell types ⌨️
Or we can insert the classification results into the SingleCellExperiment object directly which will be called type.
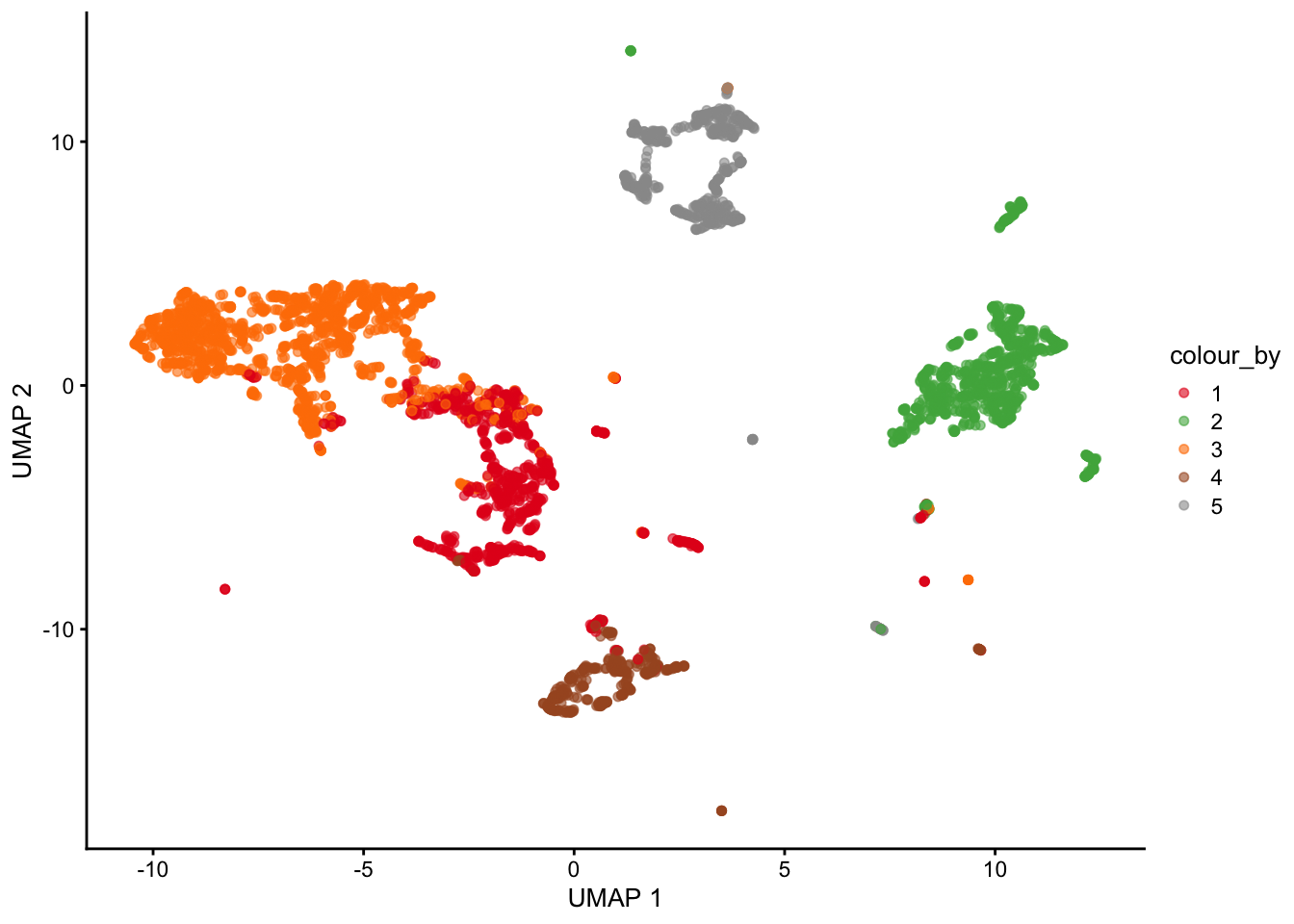
set.seed(42)sce <-clustify( sce, # seurat objectref_mat =ref_hema_microarray(), # cell type reference datacluster_col ="clusters", # column in metadata with clustersobj_out =TRUE,# use variable genes for comparisonquery_genes = top)plotUMAP(sce, colour_by ="type")
Saving and sharing objects
You can share your SingleCellExperiment objects with collaborators by saving the object as an .rds file.
If you plan on publishing the data, then the best practices are to upload the UMI count matrix and your colData() data.frame containing the cell type annotations.
To save the UMI count matrix use write10xcounts() from the DropletUtils Bioconductor package.
mat <-counts(sce)write10xCounts("path/to/output", mat)
Saving and sharing objects
When saving the colData() it is also a nice gesture to include the UMAP coordinates that you used for the main visualizations in your manuscript. The clustering and UMAP coordinates are very hard to reproduce because of the non-deterministic elements of the algorithms.