class 22
RNA-sequencing intro
2026-03-27
RNA in the cell
life fo an mRNA
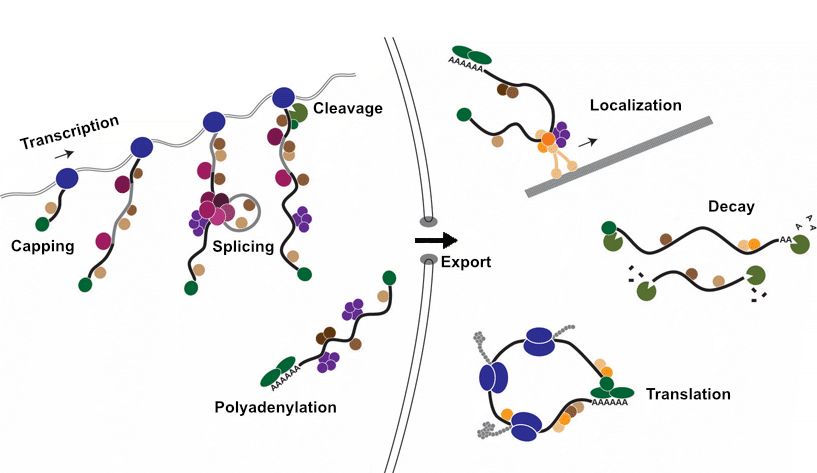
Messenger RNA (mRNA) carries genetic information encoded in DNA required for making proteins.
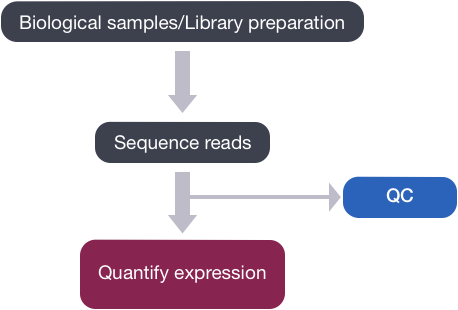
RNA-seq
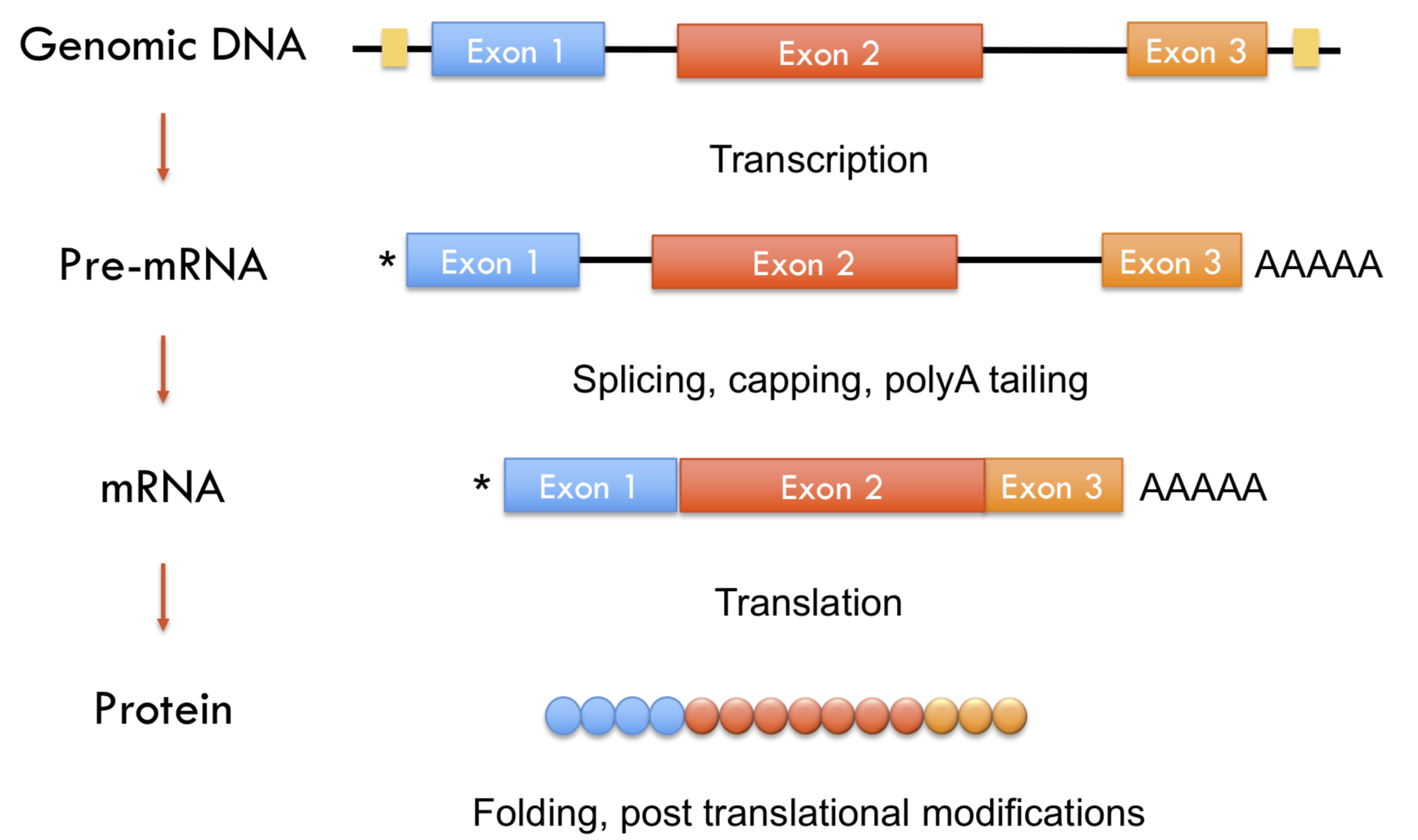
Typically refers to “long” RNAs i.e. mRNA and long non-coding RNA (lncRNA). Specifically, we capture the steady-state pool of mature mRNA and to a lesser degree pre-mRNA. Thus, we can easily assess the abundance and isoforms expressed in the sample of interest. Of course, long read RNA sequencing (Nanopore, PacBio) enable better detection of continuity of exons and full-length isoforms.
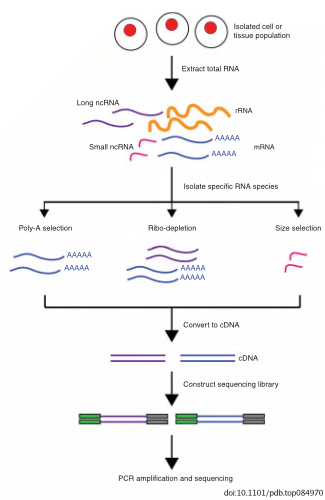
Selecting RNA populations for sequencing
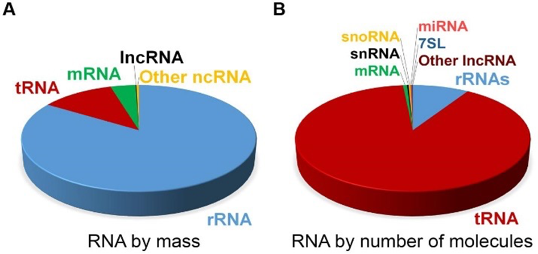
Need to determine which population of RNA you are interested in sequencing. The vast majority (~80%) of RNA in the cell is from ribosomal RNA. Smaller regulatory non-coding RNA are typically excluded due to size selection (snRNA, snoRNA, tRNA, miRNA).
polyA selection: uses oligo dT to hybridize to poly A tails of mRNA (and many long non-coding RNA)
depletion of rRNA: uses DNA oligos complementary to portions of rRNA to either remove (purification) or degrade (RNaseH) to avoid rRNA getting into the library.
size selection: sequence a population of RNAs that have a specific length such as microRNAs, which are ~21 nt regulatory non-coding RNAs.
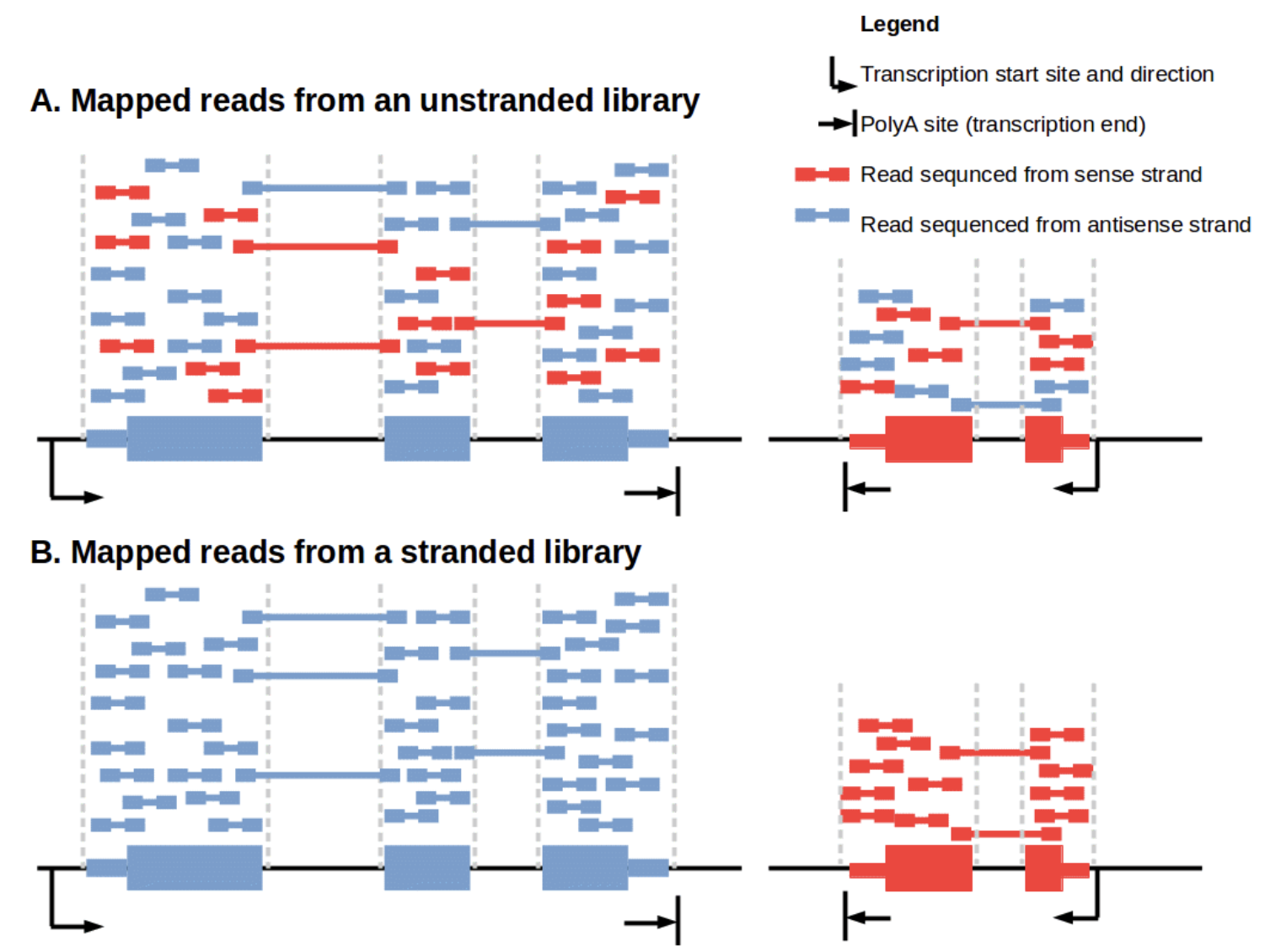
Importance of stand-specificity
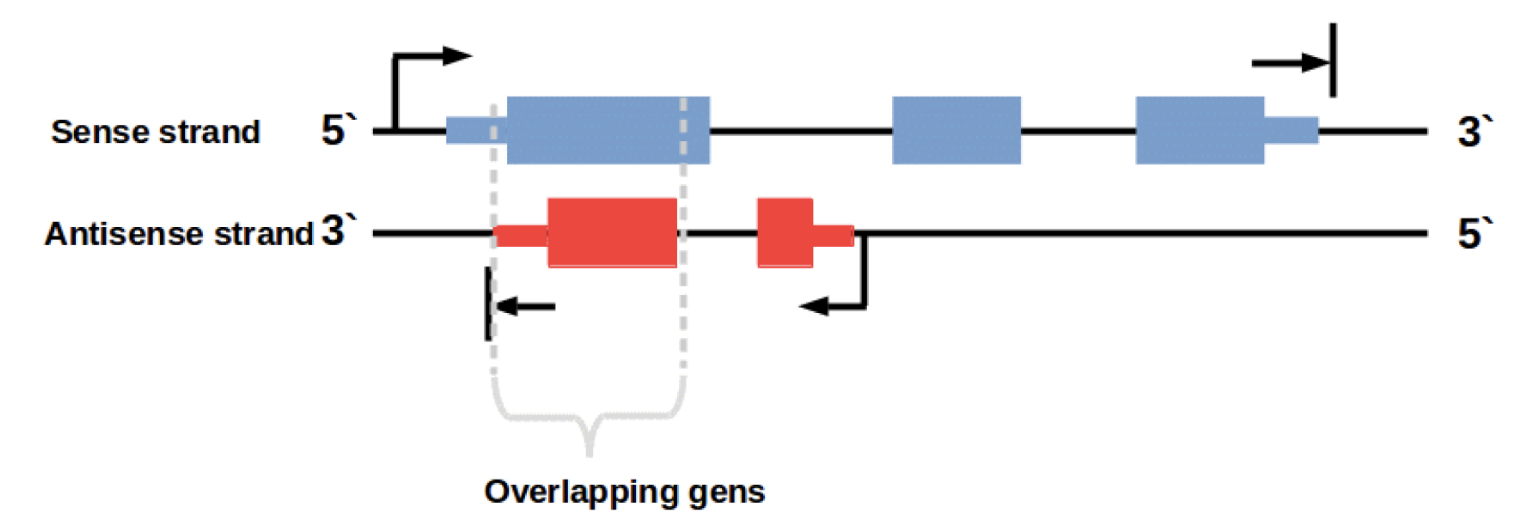
…and the genome has complex organization.
strand-specificity is crucial
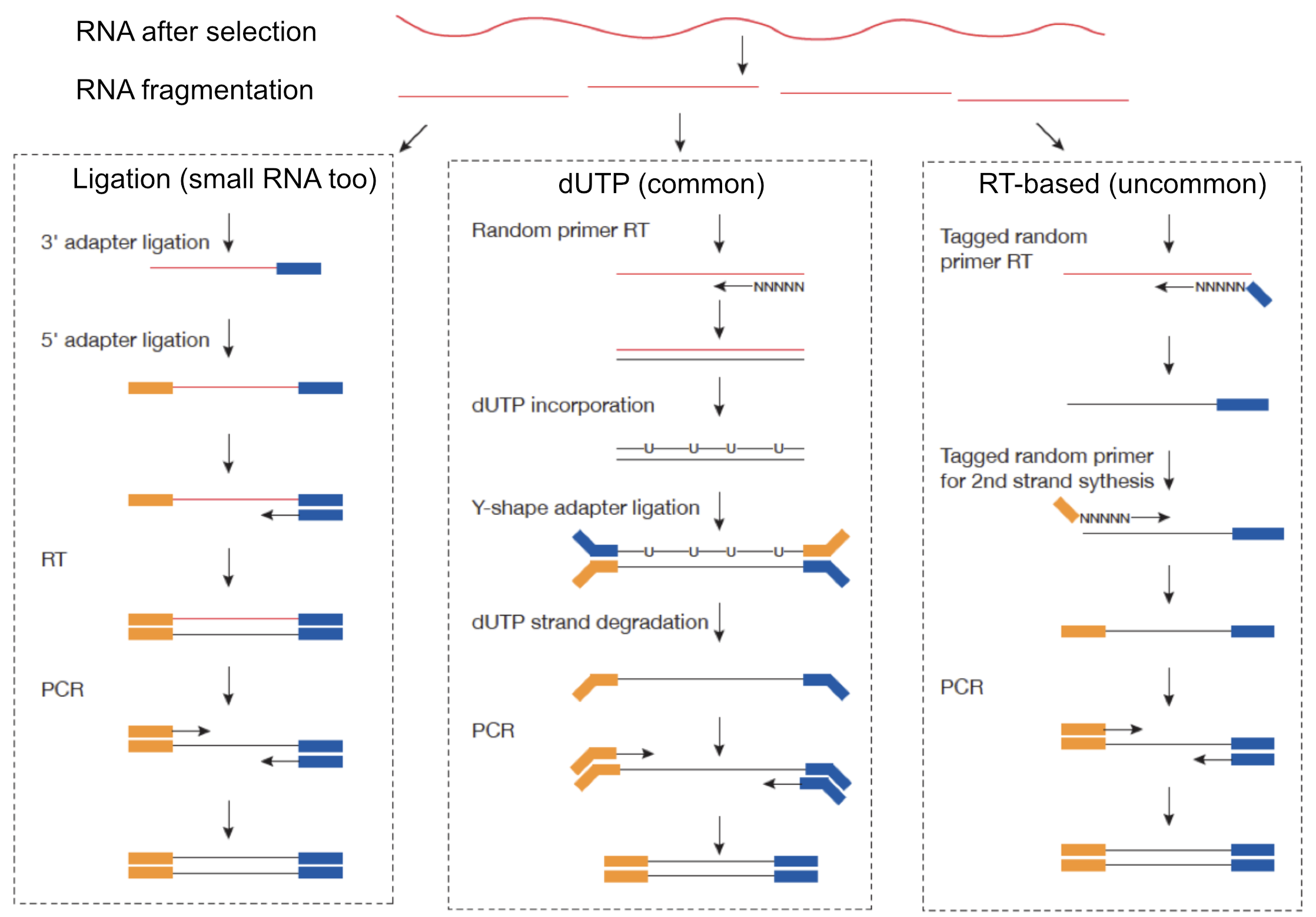
Achieving strand-specificity
RNA-seq read alignment
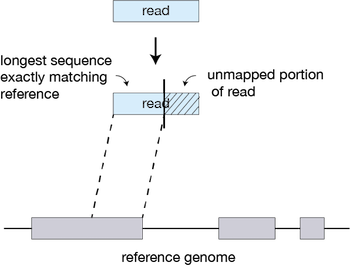
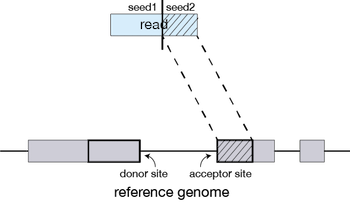
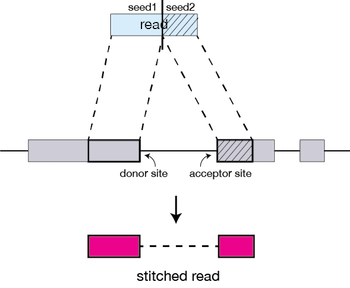
You get your data back and align the reads to the genome, right? Nope, we need to deal with reads that will need to be “split” - spliced exons - to properly align. There are two strategies to deal with this: 1) Spliced alignments and 2) Pseudoalignment (transcripts).

Spliced alignment workflow

How does STAR work?
Pseudoalignment and transcript quantification
OR align/quantify in the same step. Fast and accurate…but you need to provide the transcripts (cannot discover new isoforms).
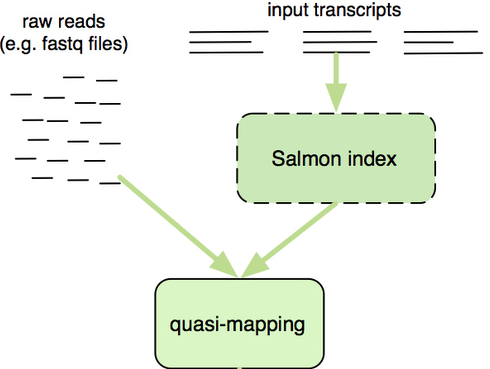
How does Salmon work?
Create an index to evaluate the sequences for all possible unique sequences of length k (k-mer) in the transcriptome from known transcripts (splice isoforms for all genes).
The Salmon index has two components:
- a suffix array (SA) of the reference transcriptome
- a hash table to map each transcript in the reference transcriptome to it’s location in the SA
The quasi-mapping approach estimates where the reads best map to on the transcriptome through identifying where informative sequences within the read map to instead of performing base-by-base alignment.
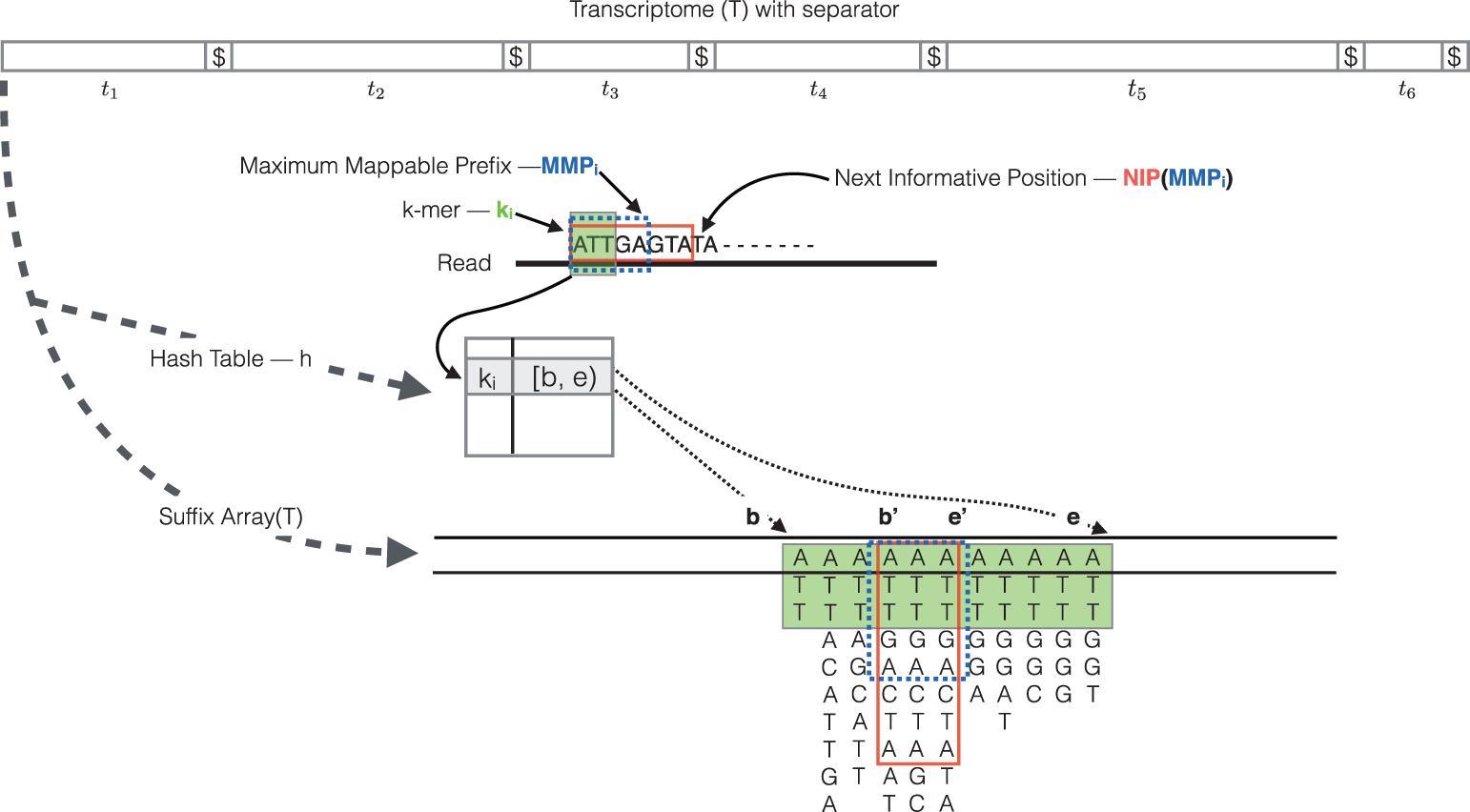
How does Salmon work? (cont.)
- The read is scanned from left to right until a k-mer that appears in the hash table is discovered.
- The k-mer is looked up in the hash table and the SA intervals are retrieved, giving all suffixes containing that k-mer
- Similar to STAR, the maximal matching prefix (MMP) is identified by finding the longest read sequence that exactly matches the reference suffixes.
How does Salmon work? (cont.)
- We could search for the next MMP at the position following the MMP, but often natural variation or a sequencing error in the read is the cause of the mismatch from the reference, so the beginning the search at this position would likely return the same set of transcripts. Therefore, Salmon identifies the next informative position (NIP), by skipping ahead 1 k-mer.
- This process is repeated until the end of the read.
- The final mappings are generated by determining the set of transcripts appearing in all MMPs for the read. The transcripts, orientation and transcript location are output for each read.
After determining the best mapping for each read/fragment, salmon will generate the final transcript abundance estimates after modeling sample-specific parameters and biases. Note that reads/fragments that map equally well to more than one transcript will have the count divided between all of the mappings; thereby not losing information for the various gene isoforms.
Sequencing Depth
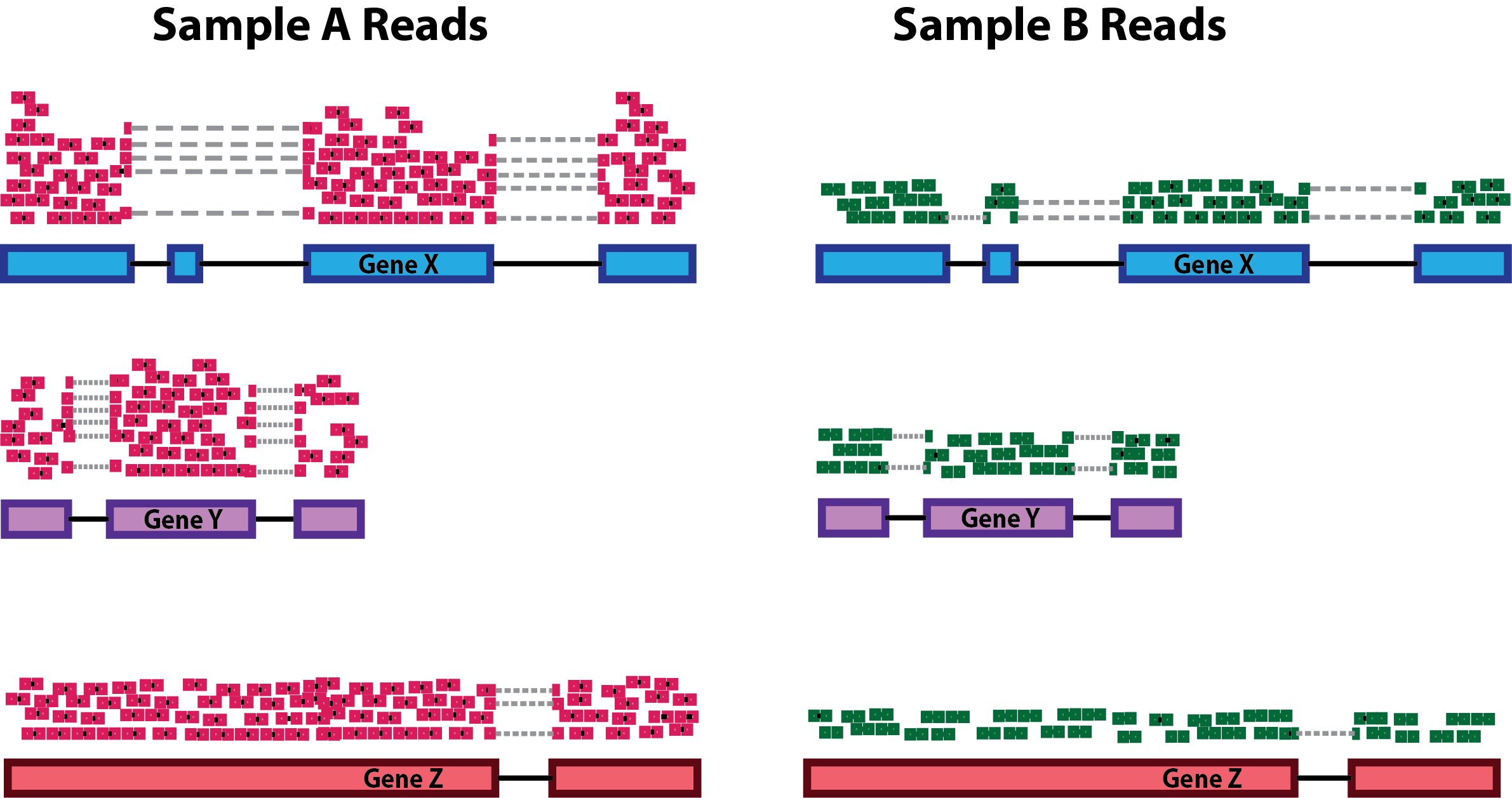
Gene length
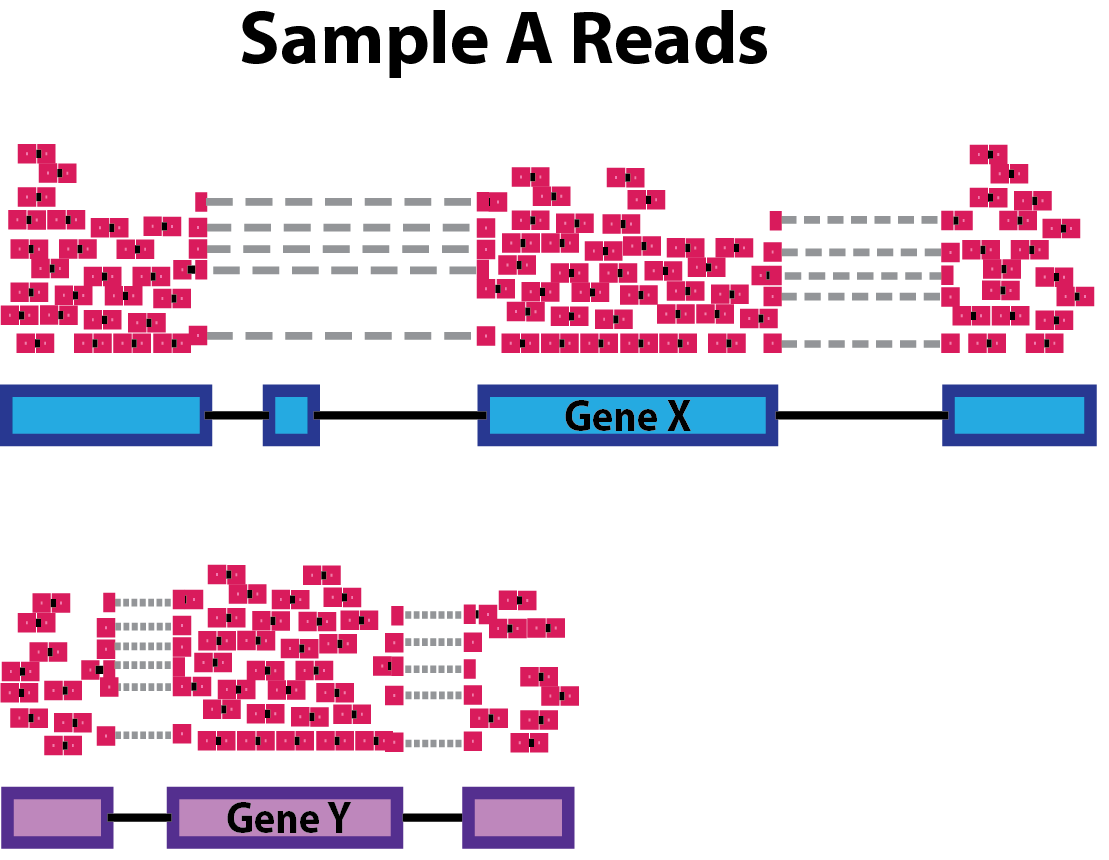
Composition

Differential expression analysis
DO NOT USE TPM (or anything we just talked about) to perform differential expression analysis.
RNA-seq data are discrete non-negative integers (counts per transcripts).
Remember the reads are (pseudo-)aligned and we COUNT how many are assigned to a specific transcript in a given sample.
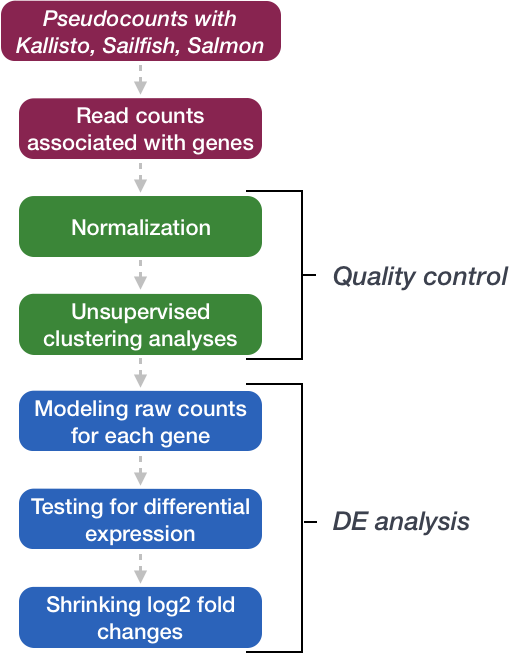
Overdispersion
Overdispersion the variance of counts is generally greater than their mean, especially for genes expressed at a higher level.
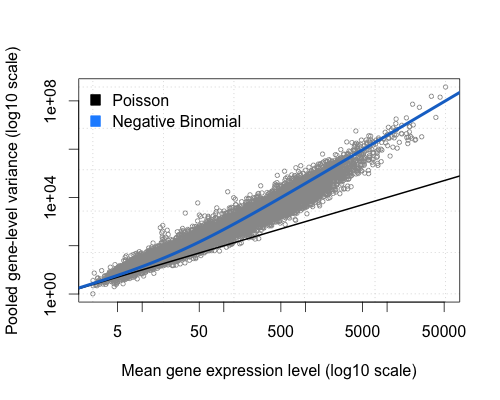
The total number of reads for each sample tends to be in the millions, while the counts per gene are much lower (many zeros, tens/hundreds) and vary considerably. While the Poisson distribution seems appropriate for sampling out of a large pool with low probability. Poisson does not handle overdispersion, enter the Negative Binomial distribution.
Examine count data
Rows: 57808 Columns: 6
── Column specification ────────────────────────────────────
Delimiter: ","
dbl (6): mock_rna_A, mock_rna_B, mock_rna_C, 8430_rna_A,...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Warning in scale_y_log10(limits = c(1, 1e+09)): log-10
transformation introduced infinite values.Warning in scale_x_log10(limits = c(1, 1e+09)): log-10
transformation introduced infinite values.Warning: Removed 6367 rows containing missing values or values
outside the scale range (`geom_point()`).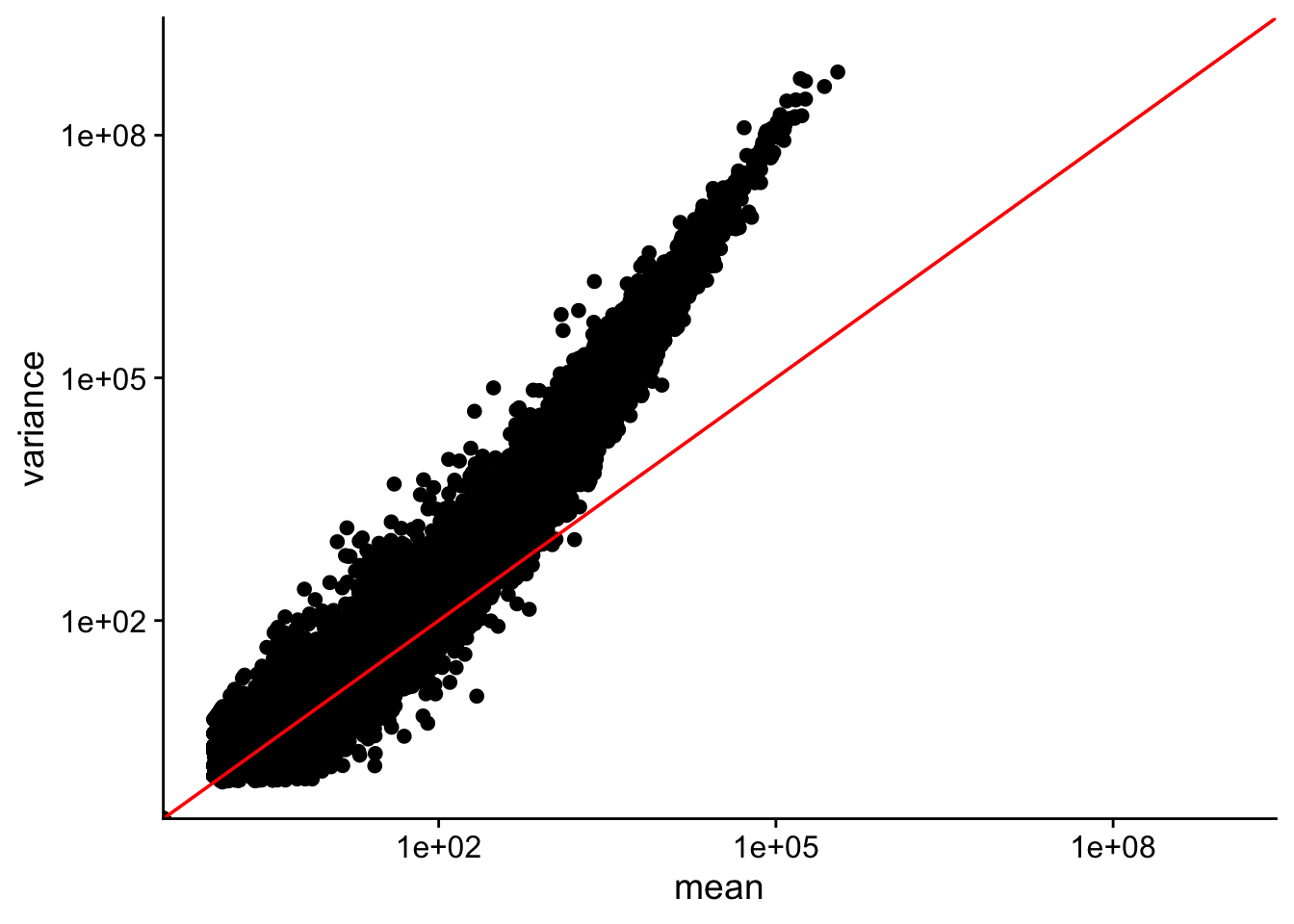
data points do not fall on the diagonal, mean != var
for highly expressed genes, var > mean
lowly expressed genes have more scatter i.e. “heteroscedasticity”.
Why do we use the negative binomial distribution for analysing RNAseq data?
DEseq Model
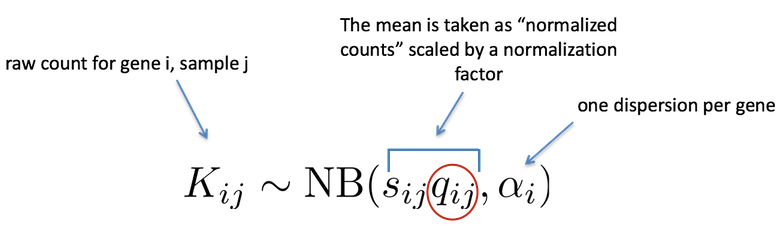
where counts \(K_{ij}\) for gene i, sample j are modeled using a negative binomial distribution with fitted mean \(\mu_{ij}\) and a gene-specific dispersion parameter \(\alpha_i\). The fitted mean is composed of a sample-specific size factor \(s_{j}\) and a parameter \(q_{ij}\) proportional to the expected true concentration of fragments for sample j.
DESeq2
\[\log_2(q_{ij}) = x_{j.} \beta_i\] The coefficients \(\beta_{i}\) give log2 fold changes for gene i `for each column of the model matrix X. Note that the model can be generalized to use sample- and gene-dependent normalization factors \(s_{ij}\).
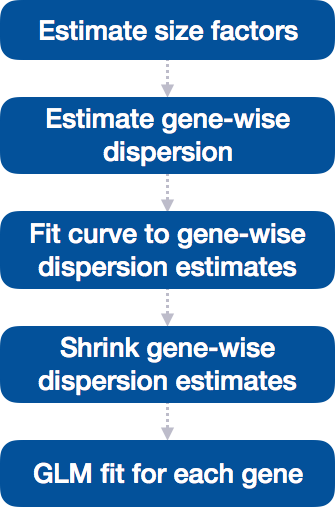
Scaling between samples
The counts divided by sample-specific size factors determined by median ratio of gene counts relative to geometric mean per gene.
Step 1: creates a pseudo-reference sample (row-wise geometric mean)
Step 2: calculates ratio of each sample to the reference
Step 3: calculate the normalization factor for each sample (size factor)
Design considerations
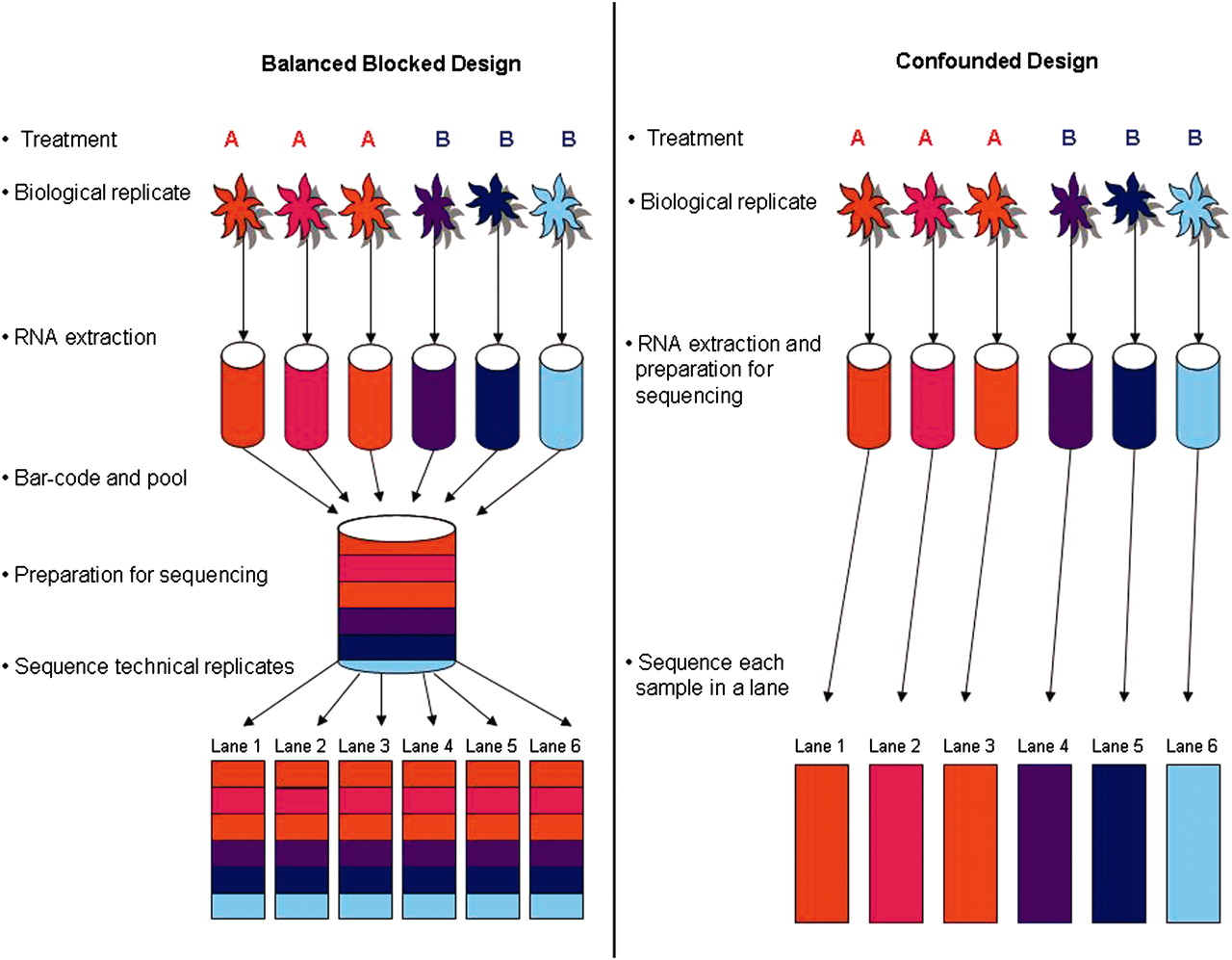
Remember ENCODE
A study compared mRNA expression profiles of many human and mouse tissues. One of their key findings:
GENE EXPRESSION IS MORE SIMILAR AMONG TISSUES WITHIN A SPECIES THAN BETWEEN CORRESPONDING TISSUES OF THE TWO SPECIES

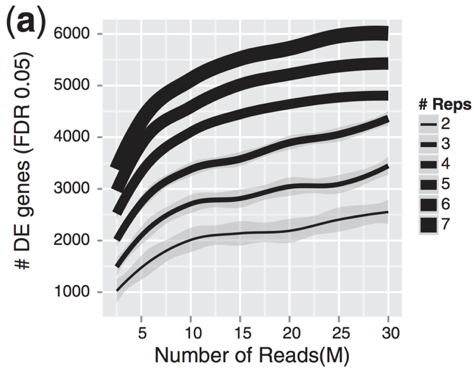
Power: depth vs reps
Replicates allow us to:
- estimate variation for each gene
- randomize out unknown covariates
- spot outliers
- improve precision of expression and fold-change estimates