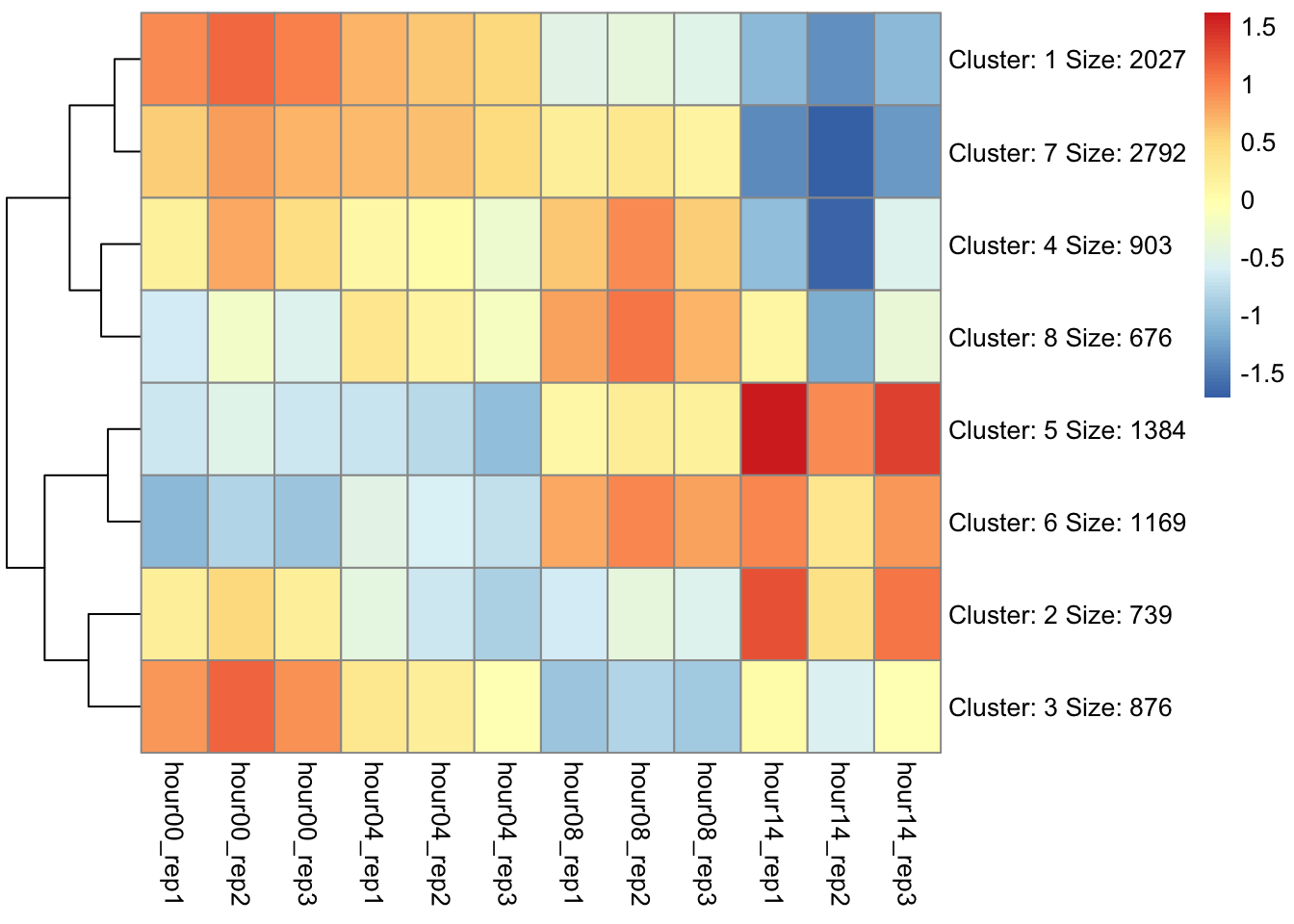
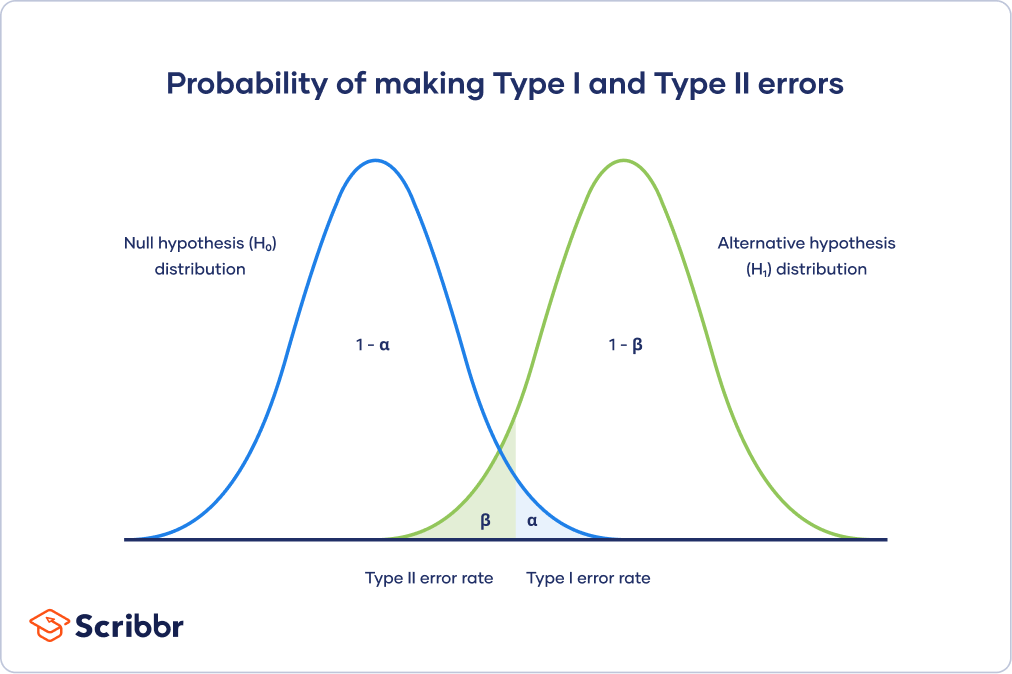
\(\alpha\) - significance level OR evidentiary standard
\(\beta\) - type II error rate, 1 - \(\beta\) is power
Different visualization
Power vs Significance
Genomics -> Lots of Data -> Lots of Hypothesis Tests
In a typical RNA-seq experiment, we test ~10K different hypotheses. For example, you have 10K genes and for each gene you test whether the mean expression changed in condition A vs condition B. Using a standard p-value cut-off of 0.05, we’d expect 500 genes to be deemed “significant” by chance. Thus, we are very concerned about False Positives or Type I Errors.
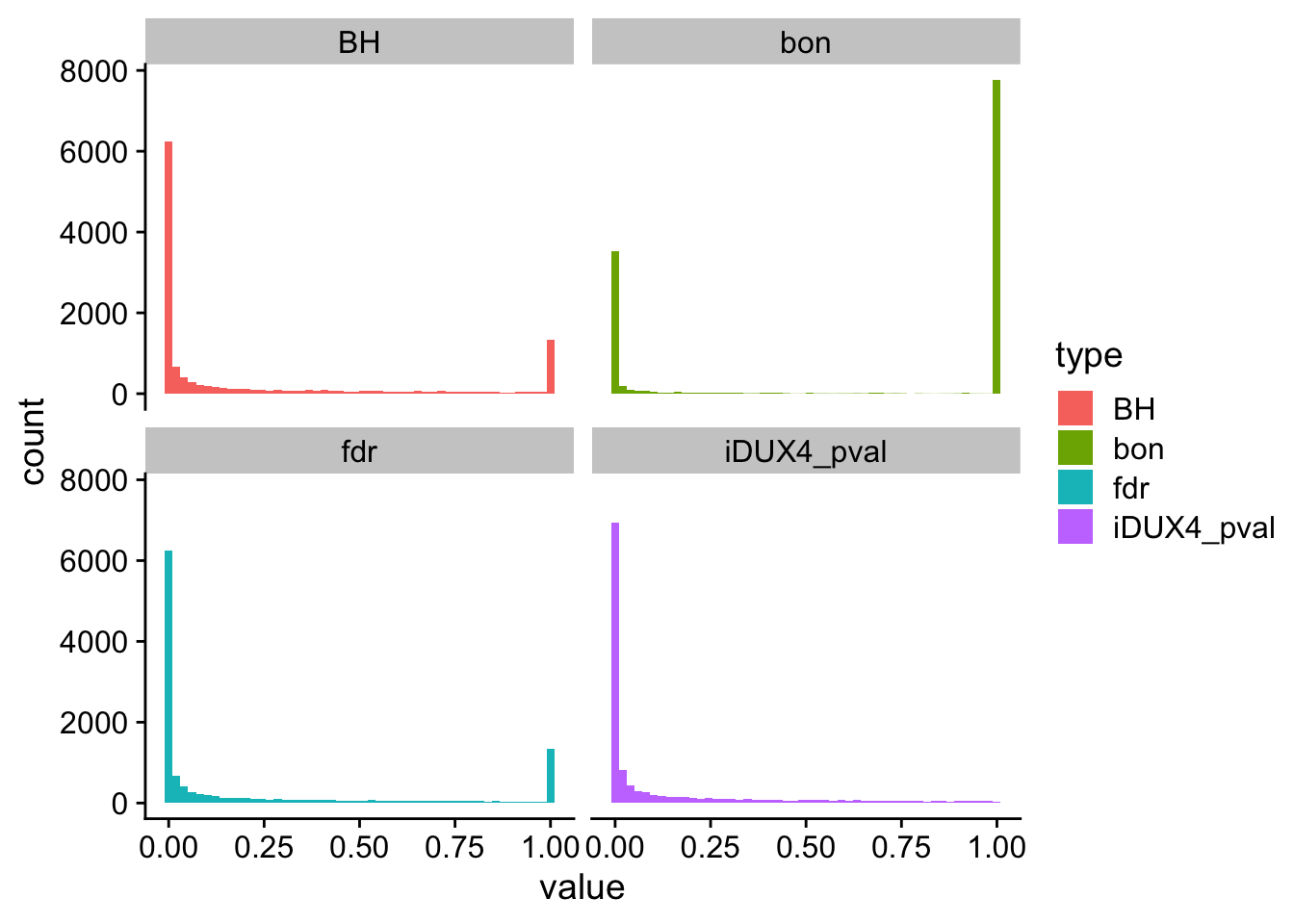
Multiple test corrections
Control overall α (also known as family-wise error rate or FWER), which will affect the α* for each test. That is, we are controlling the overall probability of making at least one false discovery. Bonferroni and Sidak corrections all control FWER.
Control false discovery rate (FDR). These procedures allow for type 1 errors (false positives) but control the proportion of these false positives in relation to true positives. This is done by adjusting the decision made for the p-value associated with each individual test to decide rejection or not. Because this will result in a higher type 1 error rate, it has higher power. This affords a higher probability of true discoveries. The step procedures control for FDR.
Bonferroni Correction
The most conservative of corrections, the Bonferroni correction is also perhaps the most straightforward in its approach. Simply divide α by the number of tests (m).
α = α/m
However, with many tests, α will become very small. This reduces power, which means that we are very unlikely to make any true discoveries.
Sidak Correction
α = 1-(1-α)^(1/m)
Holm’s Step-Down Procedure
The Holm-Bonferroni method is also fairly simple to calculate, but it is more powerful than the single-step Bonferroni.
Step 1: Order the p-values from smallest to greatest (already done)
Step 2: Calc HB for the first rank HB = .05 / 4 – 1 + 1 = .05 / 4 = .0125 H1: 0.005 < .0125, so we reject the null
Step 4: Repeat the HB formula for the second rank and keep going until we find \(H{_N}\) > \(HB{_N}\). All subsequent hypotheses are non-significant (i.e. not rejected).
Hochberg’s Step-Up Procedure
More powerful than Holm’s step-down procedure, Hochberg’s step-up procedure also seeks to control the FDR and follows a similar process, only p-values are ranked from largest to smallest.
For each ranked p-value, it is compared to the α calculated for its respective rank (same formula as Holm’s procedure). Testing continues until you reach the first non-rejected hypothesis. You would then fail to reject all following hypotheses.
Rows: 21282 Columns: 17
── Column specification ────────────────────────────────────
Delimiter: ","
chr (1): geneid
dbl (16): iDUX4_logFC, iDUX4_logCPM, iDUX4_LR, iDUX4_pva...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Warning: Removed 35800 rows containing non-finite outside the scale
range (`stat_bin()`).
Exploratory data analysis (EDA)
Our goal here is to get an top-down big picture of the similarity/differences between variables in a dataset. For example, let’s say you do RNA-seq in triplicate on 4 treatment/developmental times.
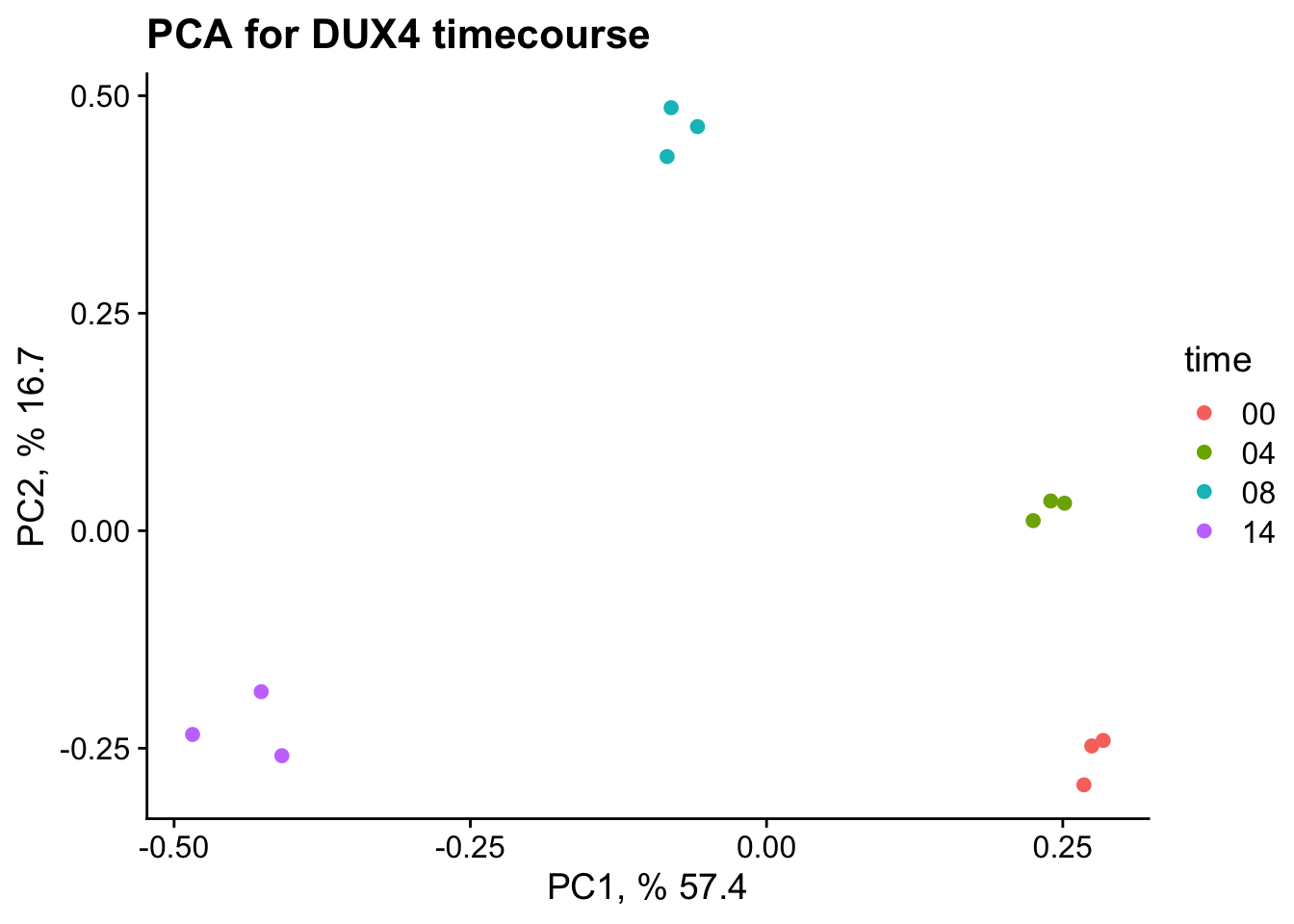
PCA
We will perform PCA on all of the samples and visualize the relationship between samples.
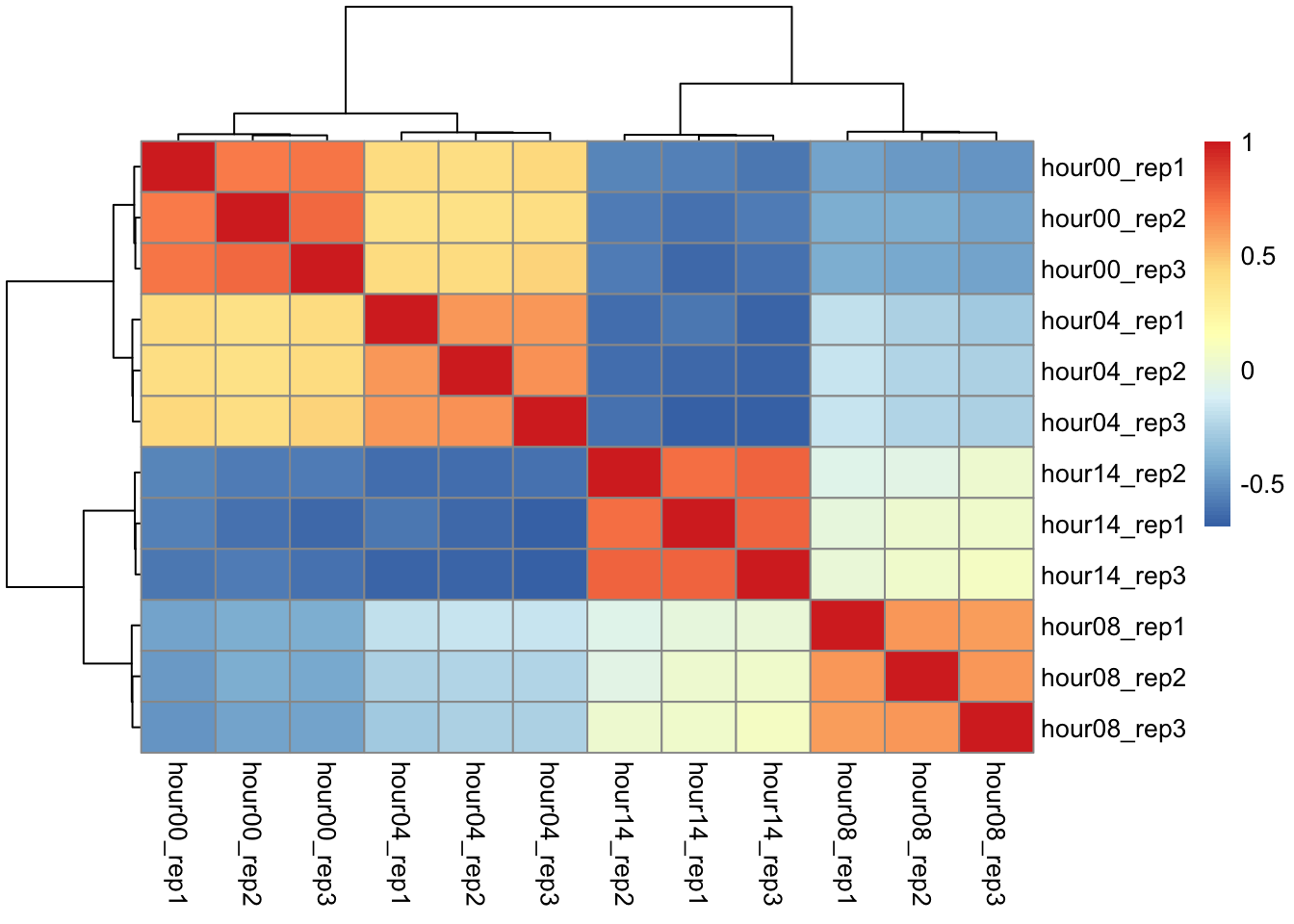
Correlation matrix
We will perform hierarchical clustering on a matrix representing the pairwise correlation between all these samples.
Explore data
Is it normal-ish?
# get dux targetsdux_targets <-read_csv(file =here("data", "target_genes.csv.gz"))
Rows: 74 Columns: 1
── Column specification ────────────────────────────────────
Delimiter: ","
chr (1): hgnc_symbol
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Rows: 10568 Columns: 13
── Column specification ────────────────────────────────────
Delimiter: "\t"
chr (1): gene_symbol
dbl (12): hour00_rep1, hour00_rep2, hour00_rep3, hour04_...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
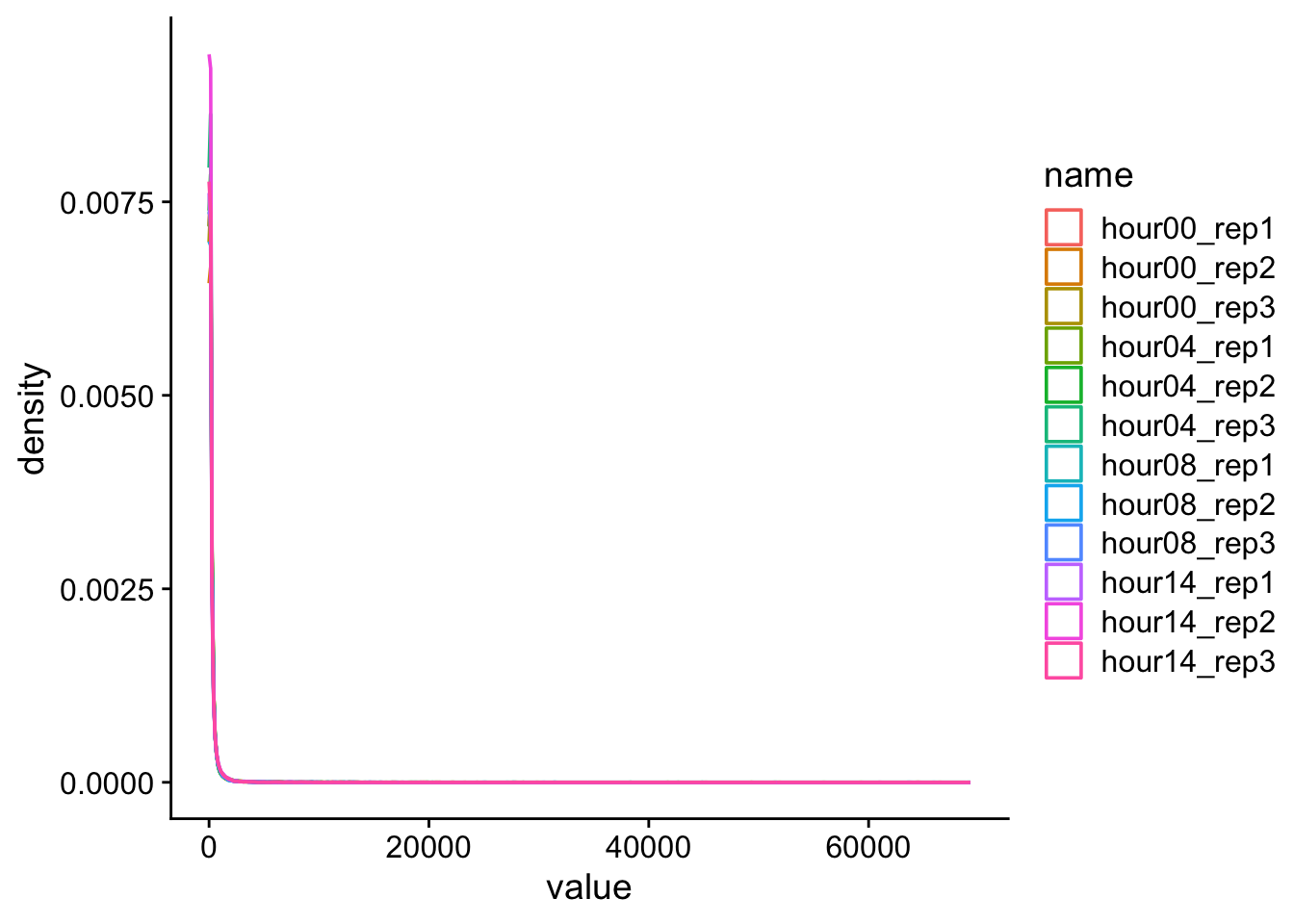
d |>pivot_longer(cols = hour00_rep1:hour14_rep3) |>ggplot(aes(x = value, color = name)) +geom_density() +theme_cowplot()
Definitely not normal
Data transformations
We often transform data to make it closer to being normally-distributed. This allows us to use more powerful statistical tests on the same data. One approach is to log-transform the data.
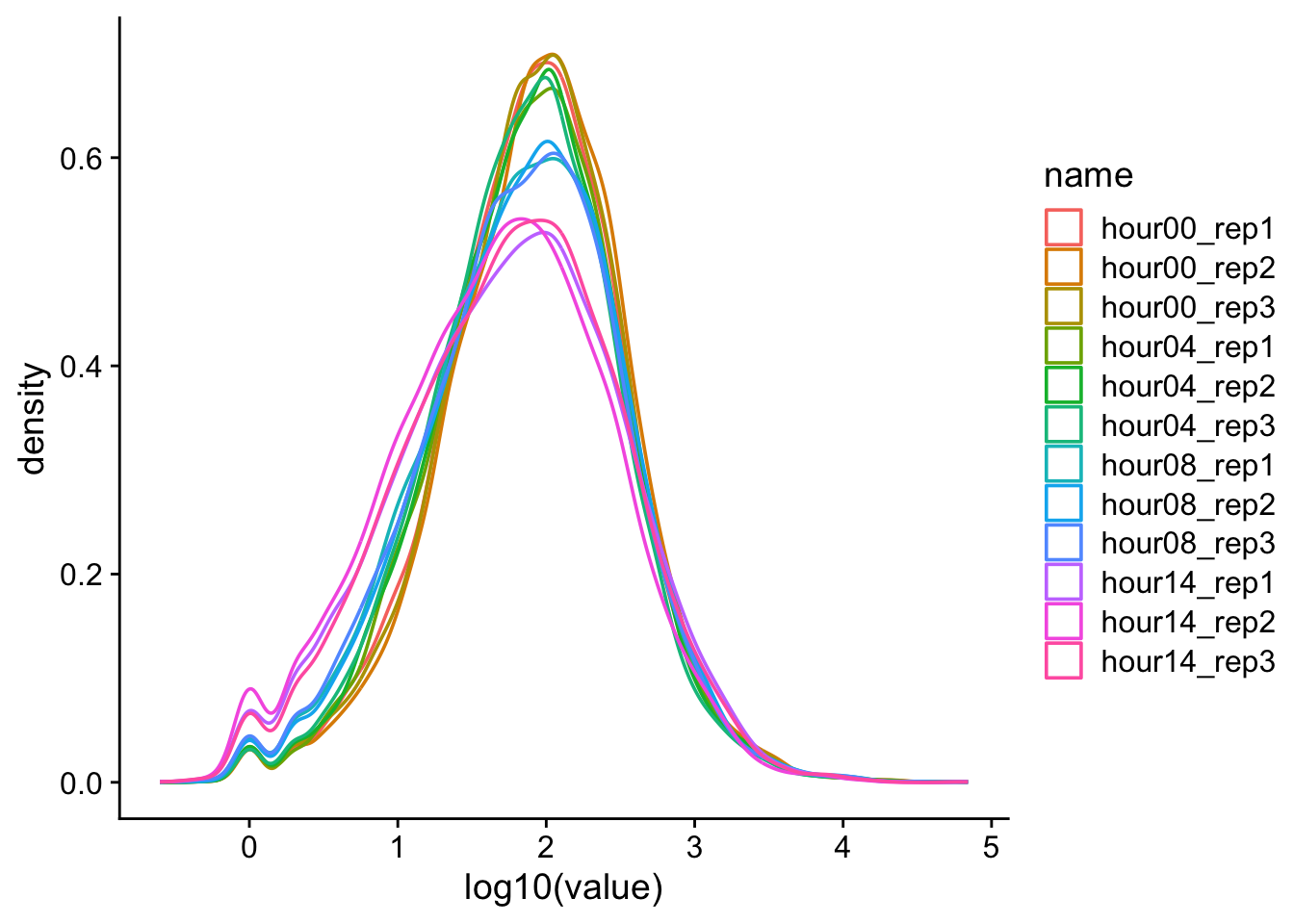
d |>pivot_longer(cols = hour00_rep1:hour14_rep3) |>ggplot(aes(x =log10(value), color = name)) +geom_density() +theme_cowplot()
Warning: Removed 1239 rows containing non-finite outside the scale
range (`stat_density()`).
\(log_{x}(0)\) is a common problem. One solution is to add a pseudocount. Since this is read count data, the smallest unit is 1 and so we will add 1 to all the observations before perforing the log transformation. \(1\) represents the pseudocount in this case.
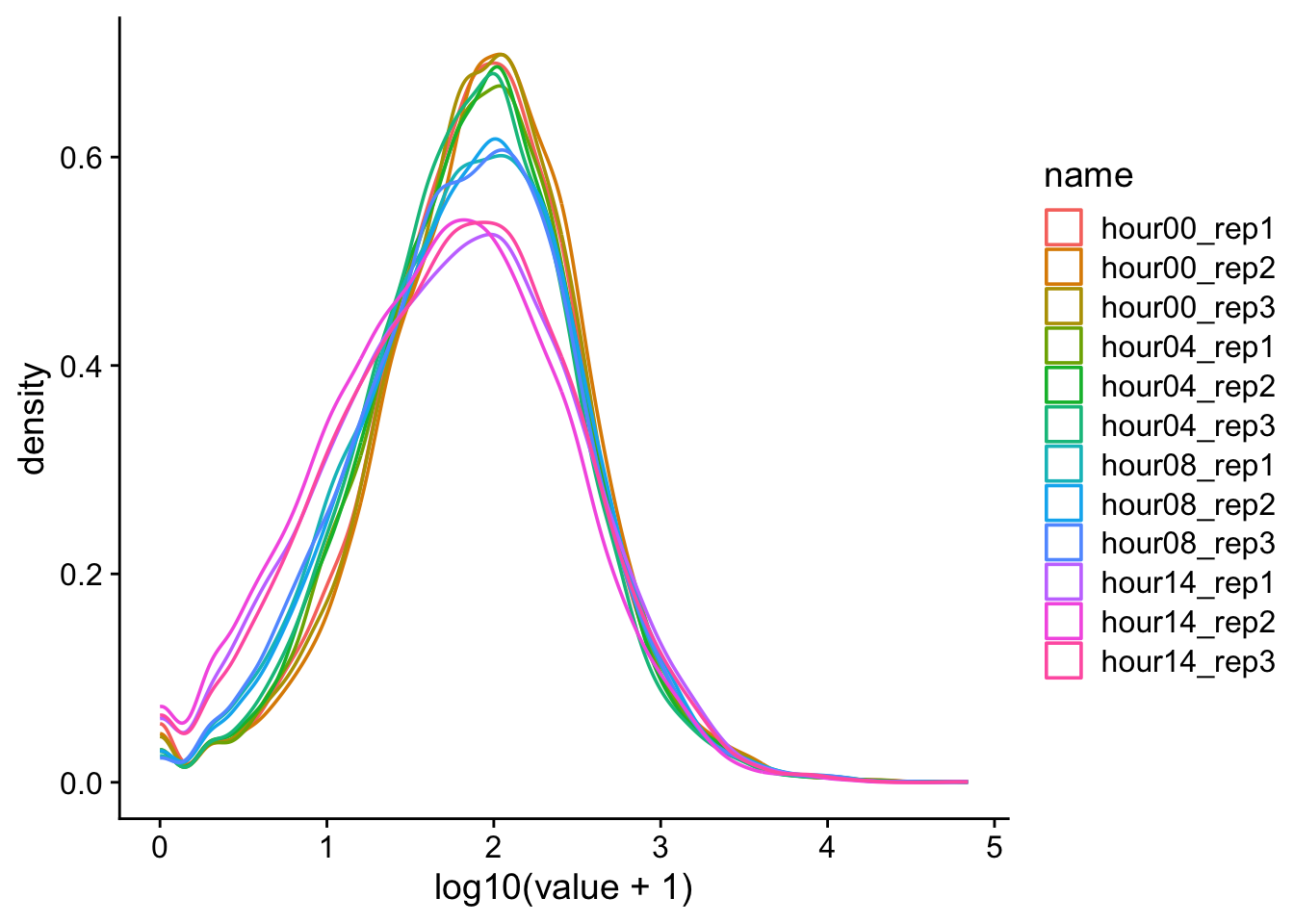
d |>pivot_longer(cols = hour00_rep1:hour14_rep3) |>ggplot(aes(x =log10(value +1), color = name)) +geom_density() +theme_cowplot()
correlation analysis
prepare the data for analysis
# pull countsx <- d |>select_if(is.numeric) |># keep only the numeric columnsmutate_all(funs(log2(1+ .))) |># log2 transformas.matrix() # matrix
correlation analysis
Warning: `funs()` was deprecated in dplyr 0.8.0.
ℹ Please use a list of either functions or lambdas:
# Simple named list: list(mean = mean, median = median)
# Auto named with `tibble::lst()`: tibble::lst(mean,
median)
# Using lambdas list(~ mean(., trim = .2), ~ median(.,
na.rm = TRUE))
# create a dataframe with the importance/explanation of variation for each PCpca_data_info <-summary(pc)$importance |>as.data.frame()pca_data_info <-round(x = pca_data_info, digits =3)# we make a dataframe out of the rotations and will use this to plotpca_plot_data <- pc$rotation |>as.data.frame() |>rownames_to_column(var ="ID") |>separate(col = ID, into =c("time", "rep"), sep ="_")# recode "rep"pca_plot_data$rep <-recode(pca_plot_data$rep,rep1 ="A",rep2 ="B",rep3 ="C")# gsub hourpca_plot_data$time <-gsub(pattern ="hour",replacement ="",x = pca_plot_data$time)ggplot(data = pca_plot_data, mapping =aes(x = PC1, y = PC2, color = time)) +geom_point() +xlab(paste("PC1, %", 100* pca_data_info["Proportion of Variance", "PC1"])) +ylab(paste("PC2, %", 100* pca_data_info["Proportion of Variance", "PC2"])) +ggtitle("PCA for DUX4 timecourse") +theme_cowplot()
PCA - prepare visualization
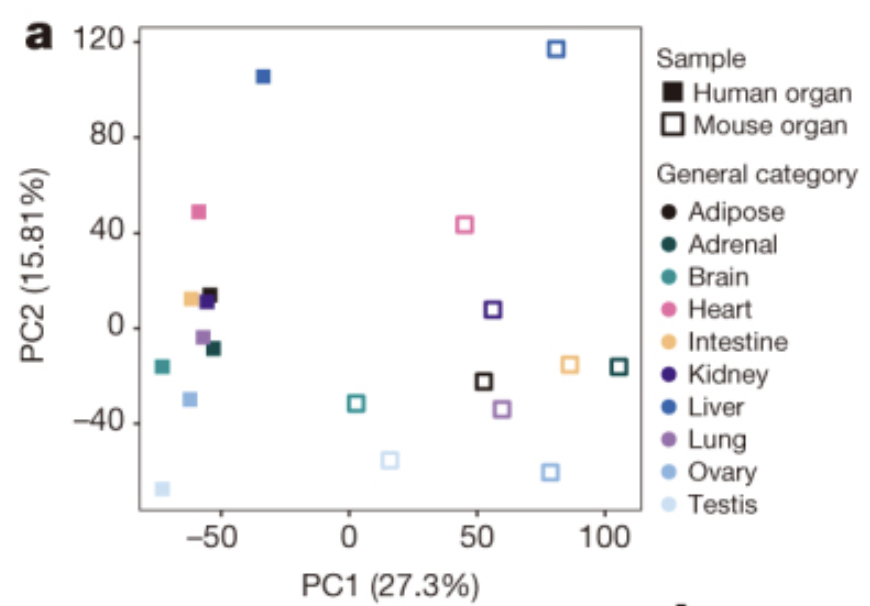
Famous PCA example
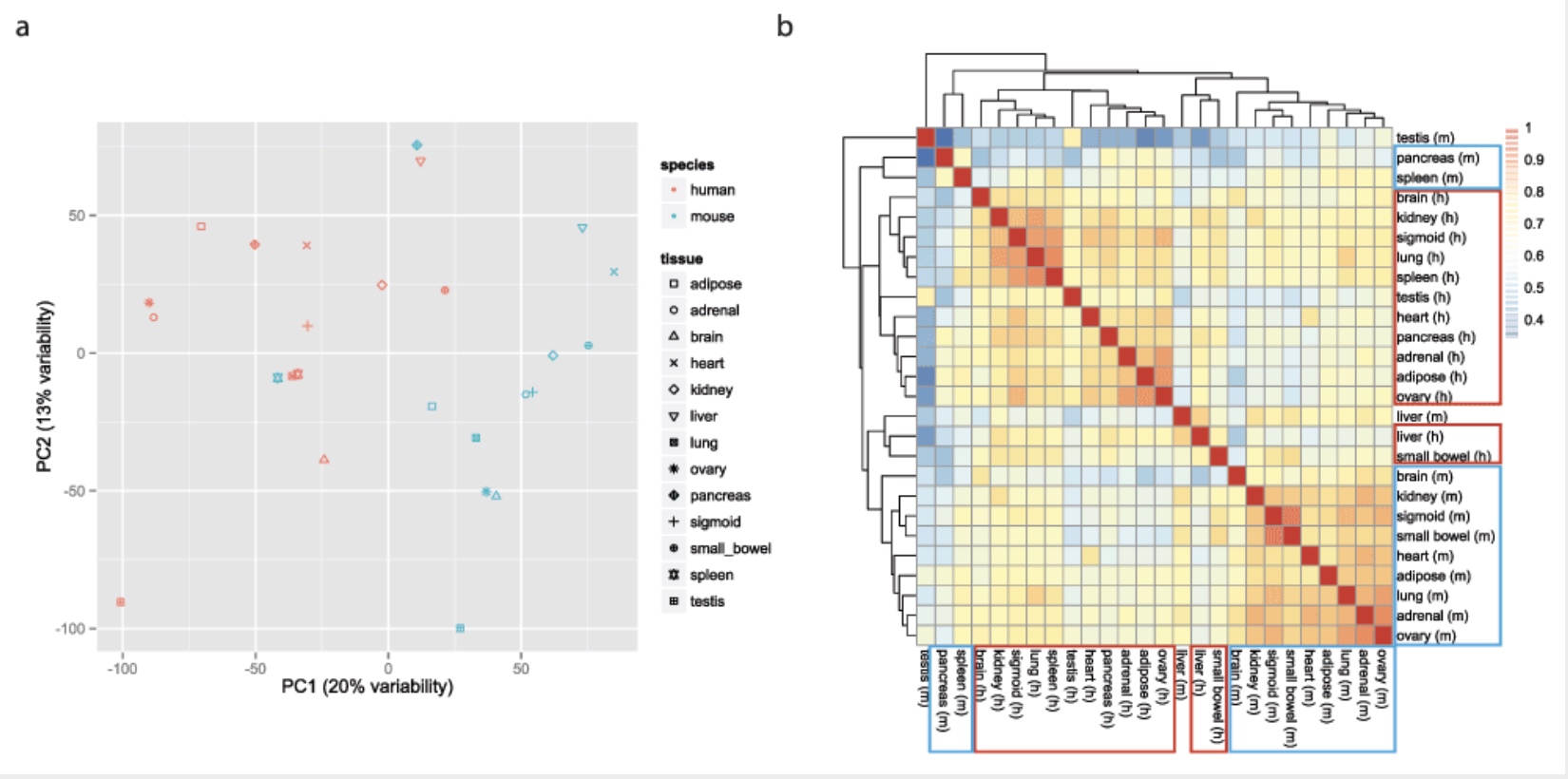
Using gene expression as your measurement, do you think the mouse liver is more similar to a mouse heart or a human liver?
The Mouse ENCODE Consortium reported that comparative gene expression data from human and mouse tend to cluster more by species rather than by tissue.
This observation was surprising, as it contradicted much of the comparative gene regulatory data collected previously, as well as the common notion that major developmental pathways are highly conserved across a wide range of species, in particular across mammals.
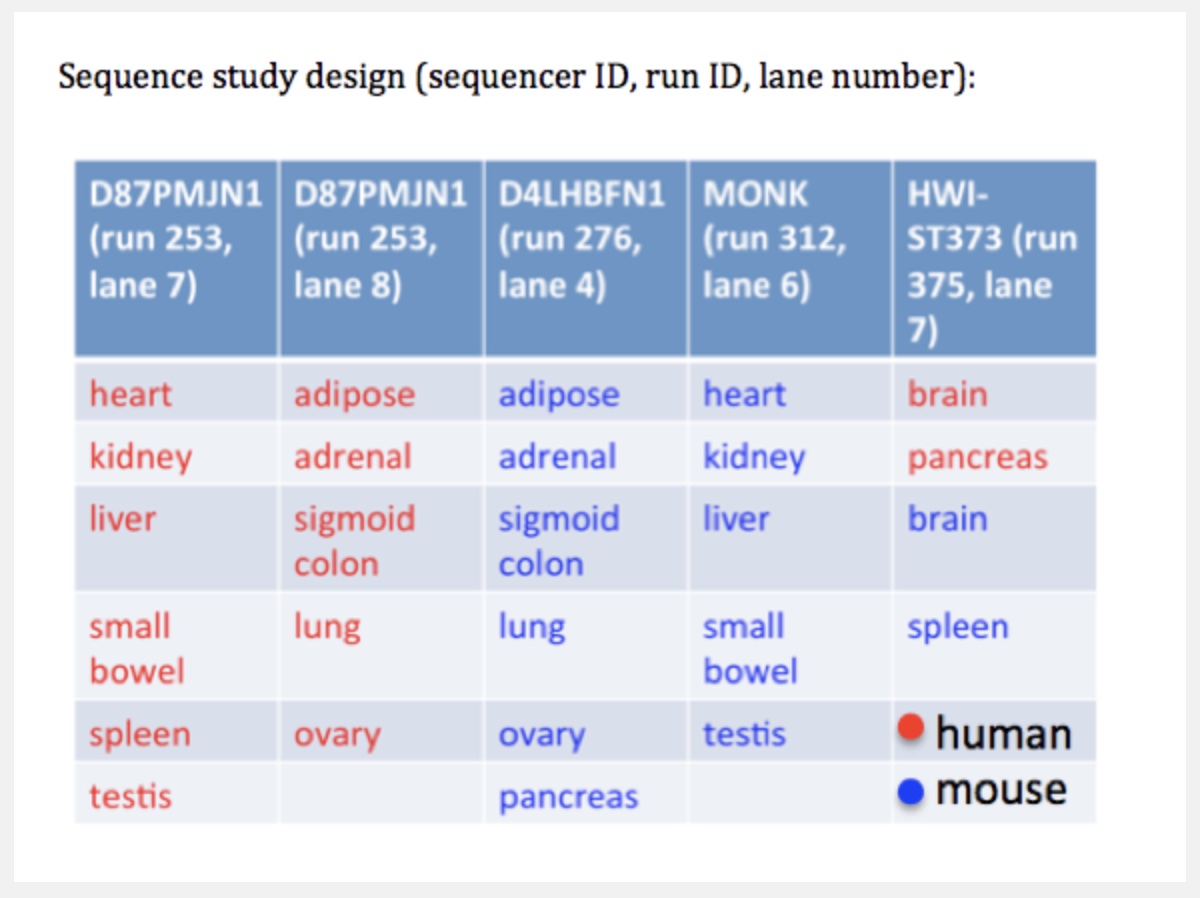
Careful with batch effects
But noticed something funny about which samples were sequenced on the same lanes.
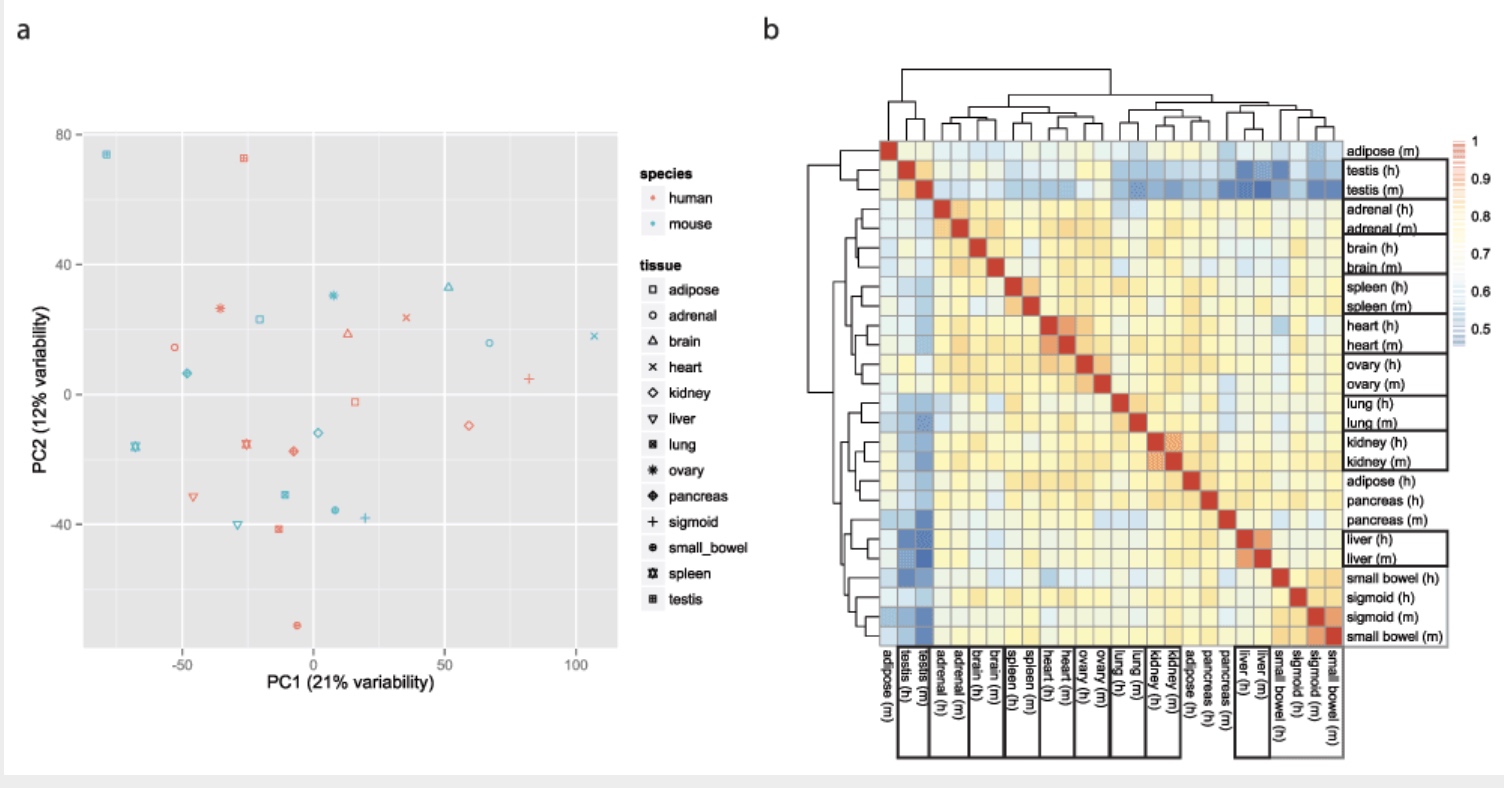
Accounting for batch effects
Here we show that the Mouse ENCODE gene expression data were collected using a flawed study design, which confounded sequencing batch (namely, the assignment of samples to sequencing flowcells and lanes) with species. When we account for the batch effect, the corrected comparative gene expression data from human and mouse tend to cluster by tissue, not by species.
K-means clustering to look for patterns
Goal: to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean, serving as a prototype of the cluster. –Wiki
K-means
K-Means data preparation
Rows are observations (individuals) and columns are variables
Any missing value in the data must be removed or estimated.
The data must be standardized (i.e., scaled) to make variables comparable.
Scaling or z-score
{%20}
\(x\) = observation \(\mu\) = population mean \(\sigma\) = population sd
We will be using this function on each row. This will allow comparison of relative changes across a row, for all rows.
K-Means clustering
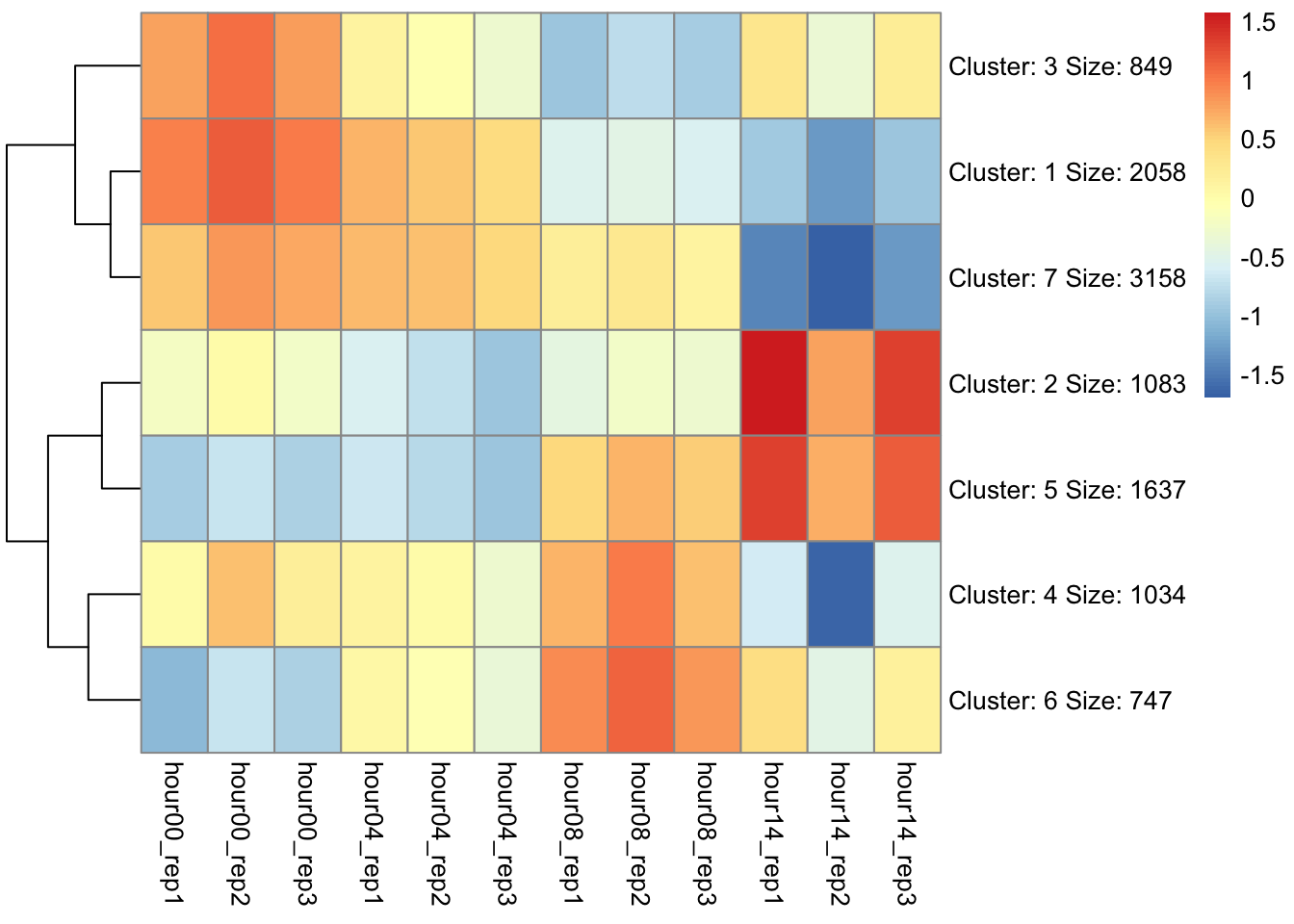
Computing k-means clustering in R (pheatmap)
Determine appropriate cluster number
Add new column with cluster number to initial data
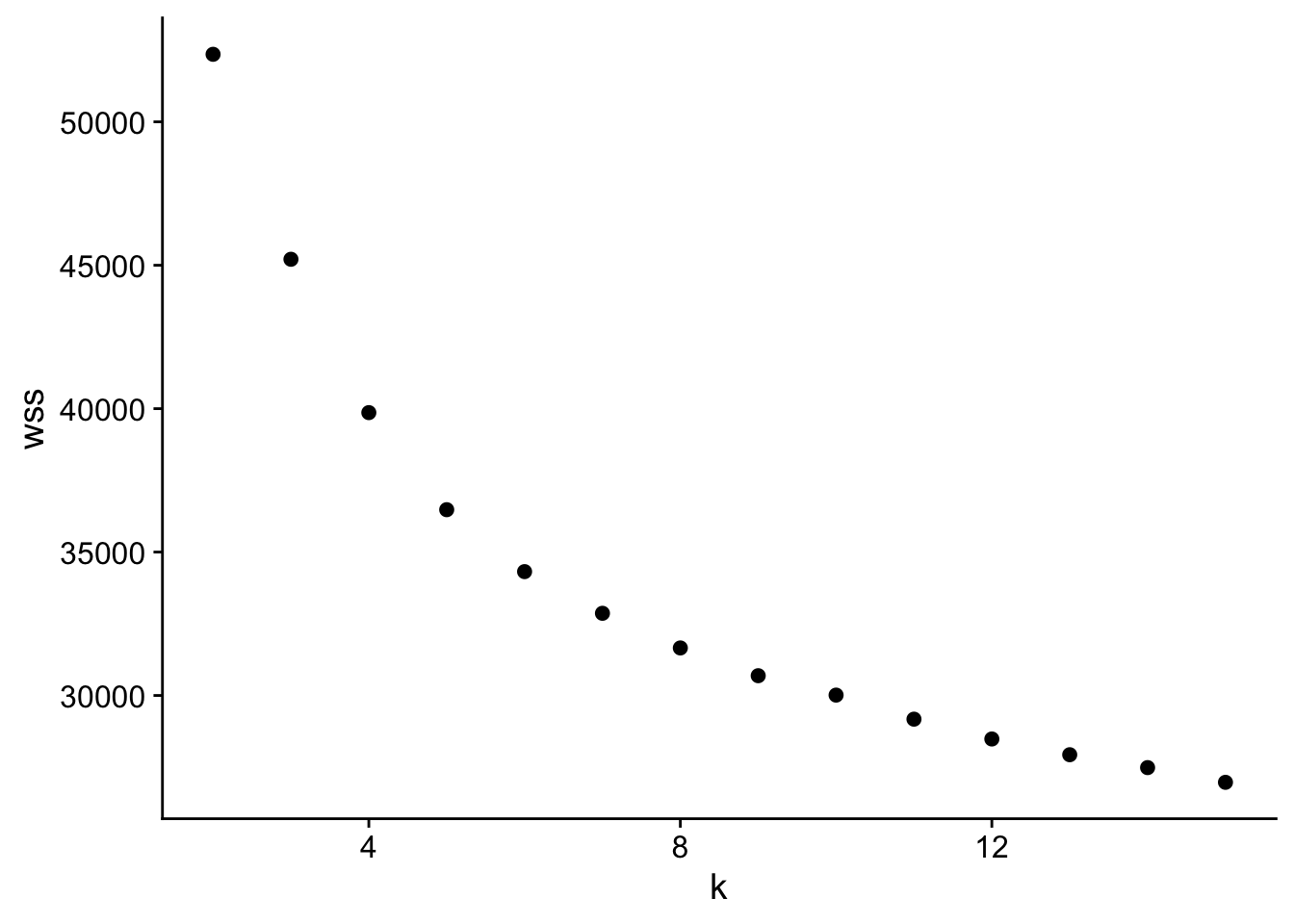
How do we figure out the optimal # clusters?
There are many methods, but we will stick with the “elbow” method.
K-means is minimizing the total within cluster sum of squares (wss).
We pick the cluster where that drop in total reaches diminishing returns -> the elbow.
# list of genes by dux4 targetingduxList <-split(cd$gene_symbol, cd$target)# list of genes by clusteringclustList <-split(cd$gene_symbol, as.factor(cd$Cluster))# calculate all overlaps between listsgom.duxclust <-newGOM(duxList, clustList,genome.size =nrow(d))getMatrix(gom.duxclust, "pval") |>t() |>as.data.frame() |>rownames_to_column(var ="clust") |>as.tibble() |>arrange(target)
Which cluster(s) contains DUX4 targets?
Warning: `as.tibble()` was deprecated in tibble 2.0.0.
ℹ Please use `as_tibble()` instead.
ℹ The signature and semantics have changed, see
`?as_tibble`.
Let’s calculate the empirical p-value of the cluster most enriched for DUX4 targets by sampling
In order to do this, you will need to:
Identify which cluster is the most enriched for DUX4 targets.
Determine how many genes are in the cluster. You will need to know this to figure out how many genes to sample from the whole data set.
Determine how many of the genes in the cluster are DUX4 targets. This is the metric that you are interested in comparing between the null distribution and your observation.
Generate 1000 random sample of the proper size from all genes and find out how many of them are DUX4 targets.
Visualize the distribution of DUX4 targets in these 1000 random (your null distribution) and overlay the number of DUX4 targets you observed in the cluster that was most enriched for DUX4 targets.
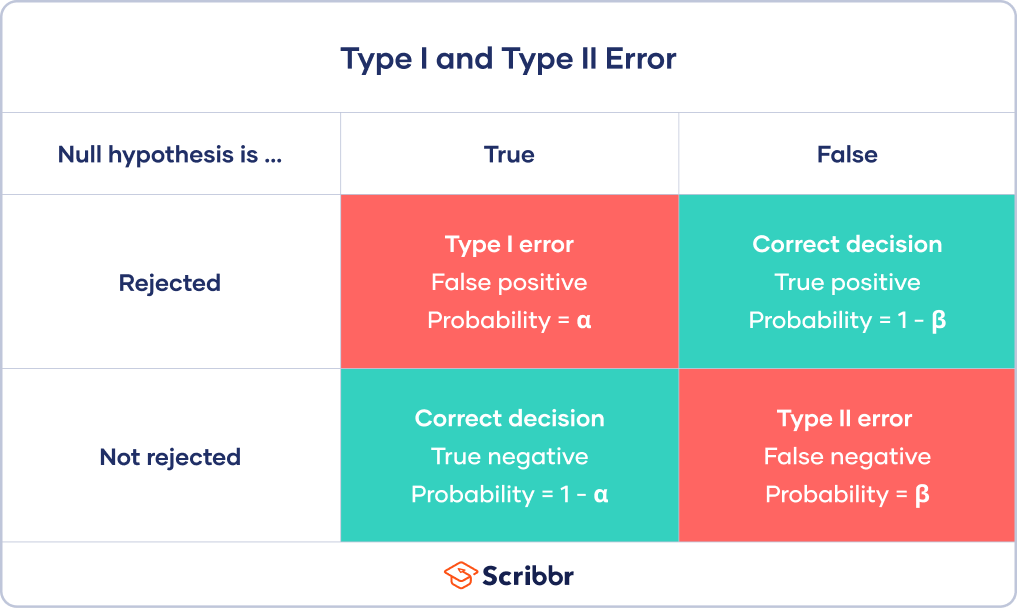
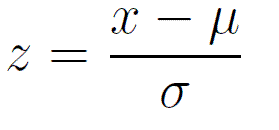 {%20}
{%20}