# we are reading the data directly from the internetbiochem <-read_tsv("http://mtweb.cs.ucl.ac.uk/HSMICE/PHENOTYPES/Biochemistry.txt",show_col_types =FALSE) |> janitor::clean_names()# simplify names a bit morecolnames(biochem) <-gsub(pattern ="biochem_",replacement ="",colnames(biochem))# we are going to simplify this a bit and only keep some columnskeep <-colnames(biochem)[c(1, 6, 9, 14, 15, 24:28)]biochem <- biochem[, keep]# get weights for each individual mouse# careful: did not come with column namesweight <-read_tsv("http://mtweb.cs.ucl.ac.uk/HSMICE/PHENOTYPES/weight",col_names = F,show_col_types =FALSE)# add column namescolnames(weight) <-c("subject_name", "weight")# add weight to biochem table and get rid of NAs# rename gender to sexb <-inner_join(biochem, weight, by ="subject_name") |>na.omit() |>rename(sex = gender)
Learning objectives
Formulate and Execute null hypothesis testing
Identify and Perform the proper statistical test for data type/comparison
Calculate and Interpret p-values
Parametric vs Nonparametric tests
Parametric tests are suitable for normally distributed data.
Nonparametric tests are suitable for any continuous data. Though these tests have their own sets of assumption, you can think of Nonparametric tests as the ranked versions of the corresponding parametric tests.
Response Variable ( y - aka dependent or outcome variable): this variable is predicted or its variation is explained by the explanatory variable. In an experiment, this is the outcome that is measured following manipulation of the explanatory variable.
Explanatory Variable ( x - aka independent or predictor variable): explains variations in the response variable. In an experiment, it is manipulated by the researcher.
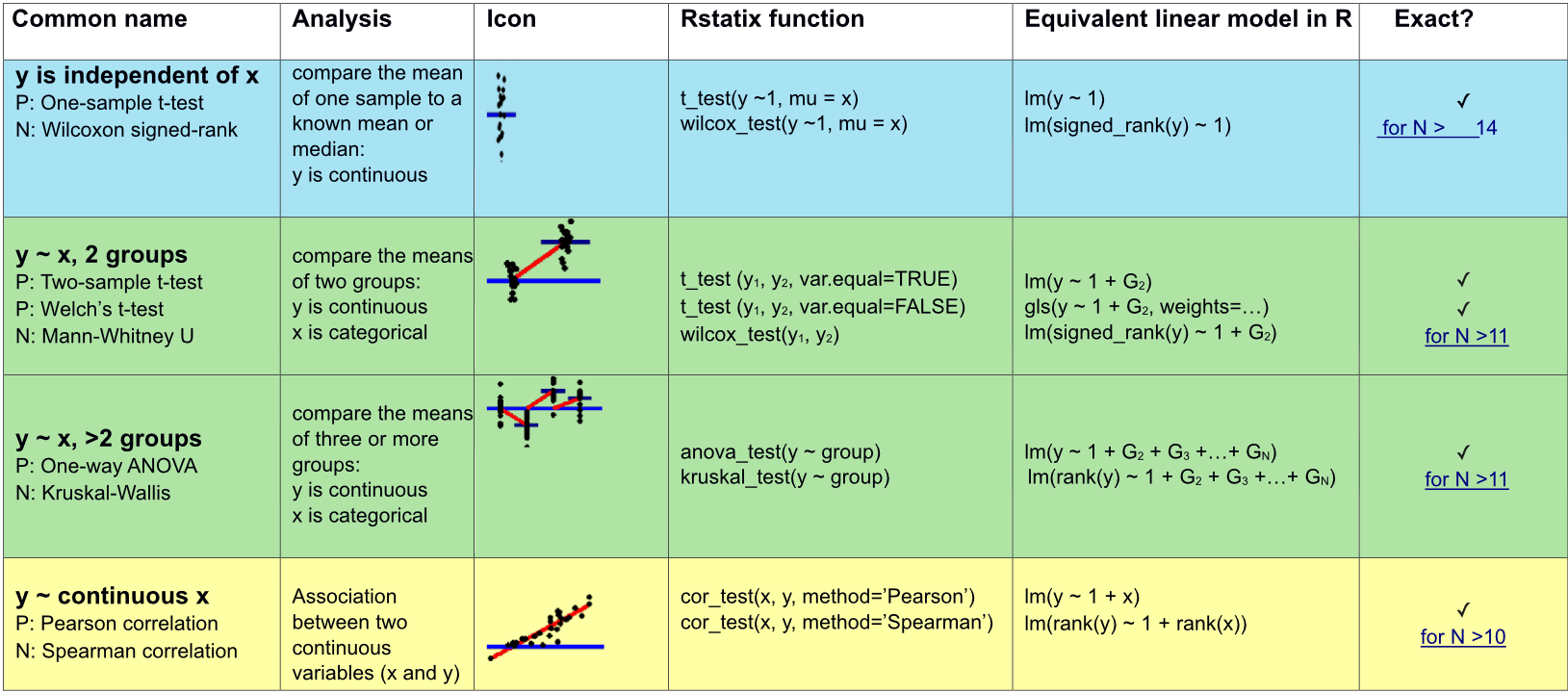
Appropriate statistical test cheatsheet
Relationship between 2 or more quantitative variables?
Correlation: summarize the direction and strength of the relationships between 2 or more variables.
Regression: build model/formula to predict a response, \(y\), from one or more explanatory variable \(x\).
Association between two continuous variables (x and y)
How an response variable is numerically related to explanatory variable(s)
Usage
To represent linear relationship between two variables
To fit a best line and estimate one variable on the basis of another variable
Response vs Explanatory variables
Doesn’t matter
must define (i.e. order of relationship matters)
Interpretation
Correlation coefficient indicates direction and extent to which two variables move together
Regression indicates the impact of a unit change in the explanatory variable (x) on the response variable (y)
Goal
To find a numerical value expressing the relationship between variables
To estimate values of response variable on the basis of the values of explanatory variable(s)
Null hypothesis testing
Examine and specify the variable(s)
Declare null hypothesis \(\mathcal{H}_0\)
Calculate test-statistic, exact p-value
We will not stick to this super closely for correlation, but will for regression.
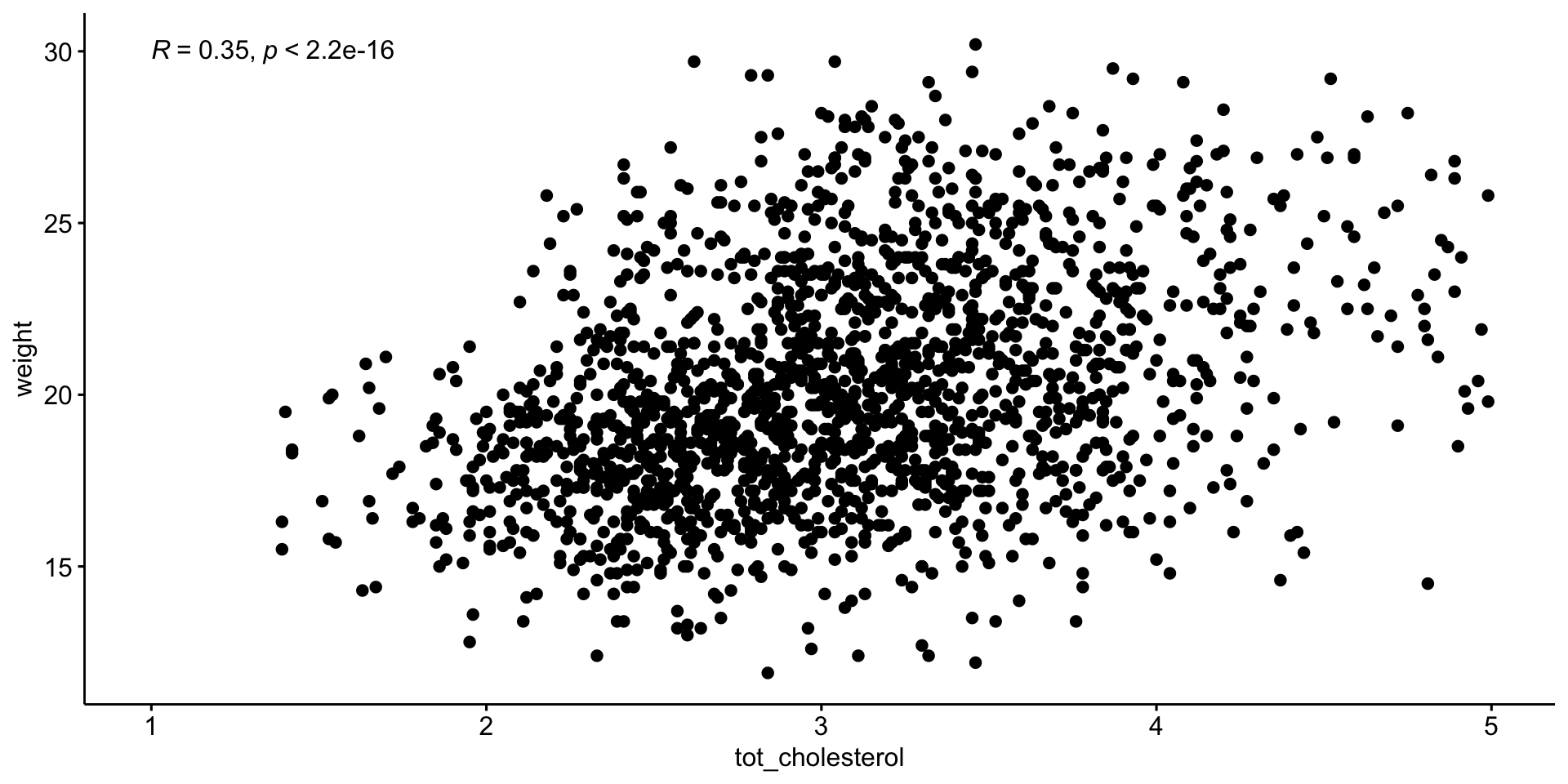
Pearson correlation
It was developed by Karl Pearson from a related idea introduced by Francis Galton in the 1880s, and for which the mathematical formula was derived and published by Auguste Bravais in 1844.[a][6][7][8][9] The naming of the coefficient is thus an example of Stigler’s Law (see list of examples here).
# mean total cholesterolm_chol <-mean(b$tot_cholesterol)# average weightm_weight <-mean(b$weight)# difference from mean total cholesteroldiff_chol <- b$tot_cholesterol - m_chol# difference from mean total cholesteroldiff_weight <- b$weight - m_weight# follow formula abovemanual_pearson <-sum(diff_chol * diff_weight) / (sqrt(sum(diff_chol^2)) *sqrt(sum(diff_weight^2)))manual_pearson
Manual calculation of Pearson correlation
[1] 0.3540731
Spearman Correlation (nonparametric)
Spearman’s rank correlation coefficientor Spearman’s ρ, named after Charles Spearman is a nonparametric measure of rank correlation (statistical dependence between the rankings of two variables). It assesses how well the relationship between two variables can be described using a monotonic function.
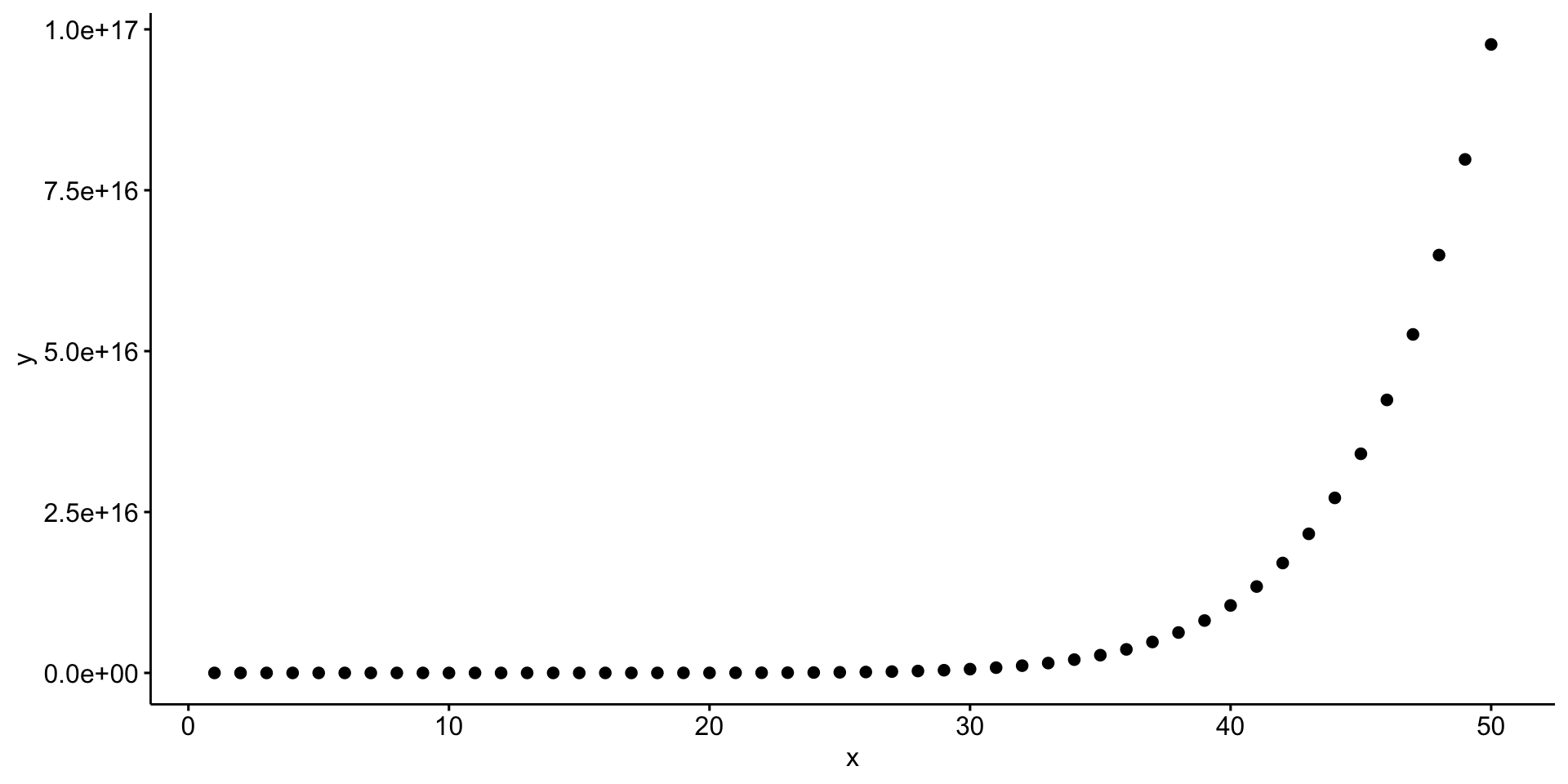
create tibble \(d\) with variables \(x\) and \(y\)
\(x\), 1:50
\(y\), which is \(x^{10}\)
d <-tibble(x =seq(1:50),y = x^10)
scatter plot
ggscatter(data = d, x ="x", y ="y")
Pearson
d |>cor_test(x, y, method ="pearson") |>select(cor)
# A tibble: 1 × 1
cor
<dbl>
1 0.67
Spearman
d |>cor_test(x, y, method ="spearman") |>select(cor)
# A tibble: 1 × 1
cor
<dbl>
1 1
Additional examples with correlation
compare 1 variable to all other quantitative variables
b |>cor_test(weight, method ="spearman") |>gt()
var1
var2
cor
statistic
p
method
weight
calcium
0.110
842963811
7.02e-06
Spearman
weight
glucose
0.120
826420593
1.60e-07
Spearman
weight
sodium
0.190
761019970
1.99e-16
Spearman
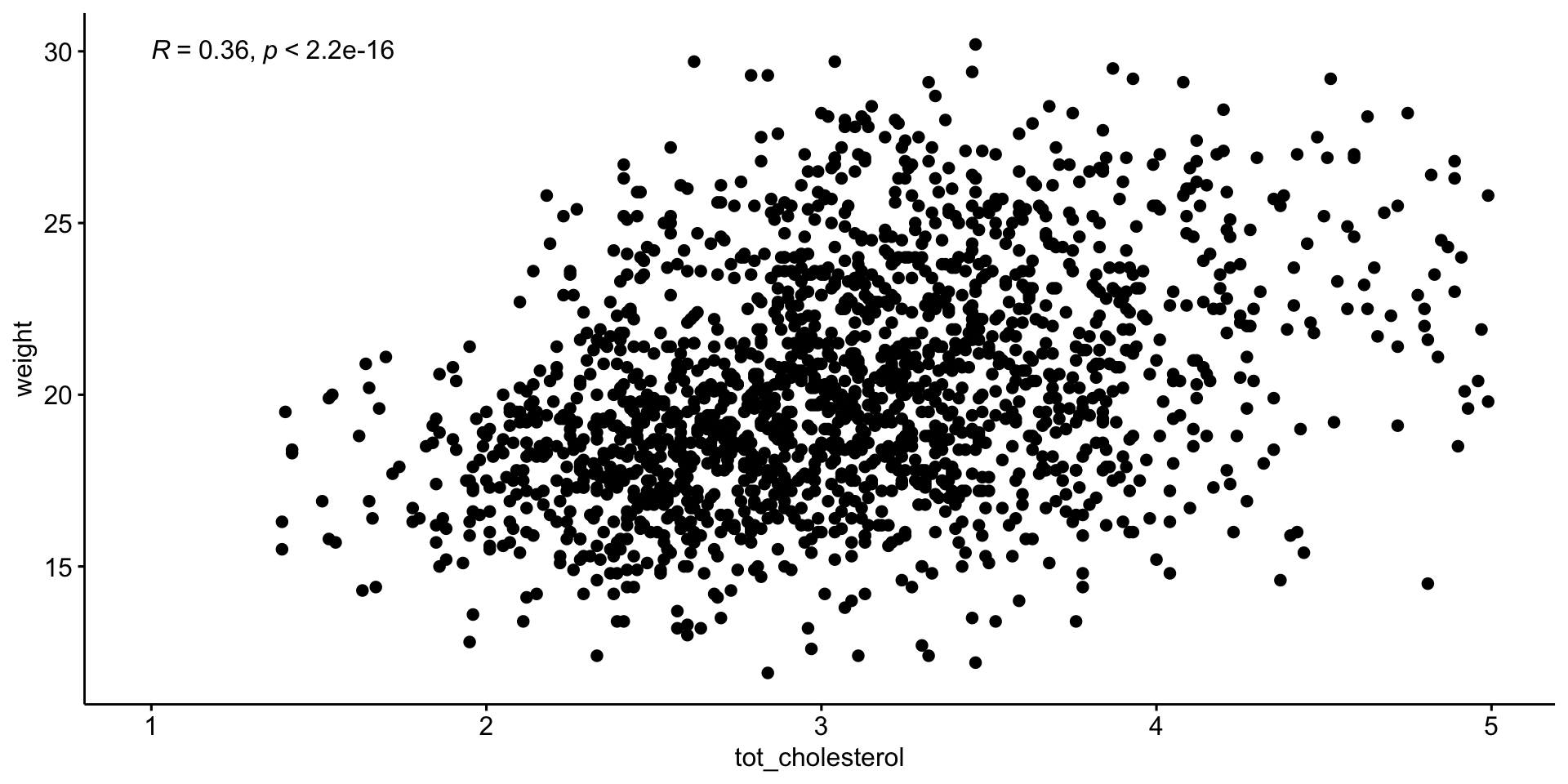
weight
tot_cholesterol
0.360
603954134
1.54e-55
Spearman
weight
age
0.150
798746789
8.23e-11
Spearman
weight
cage_density
-0.100
1039415036
1.58e-05
Spearman
weight
litter
-0.035
976251231
1.38e-01
Spearman
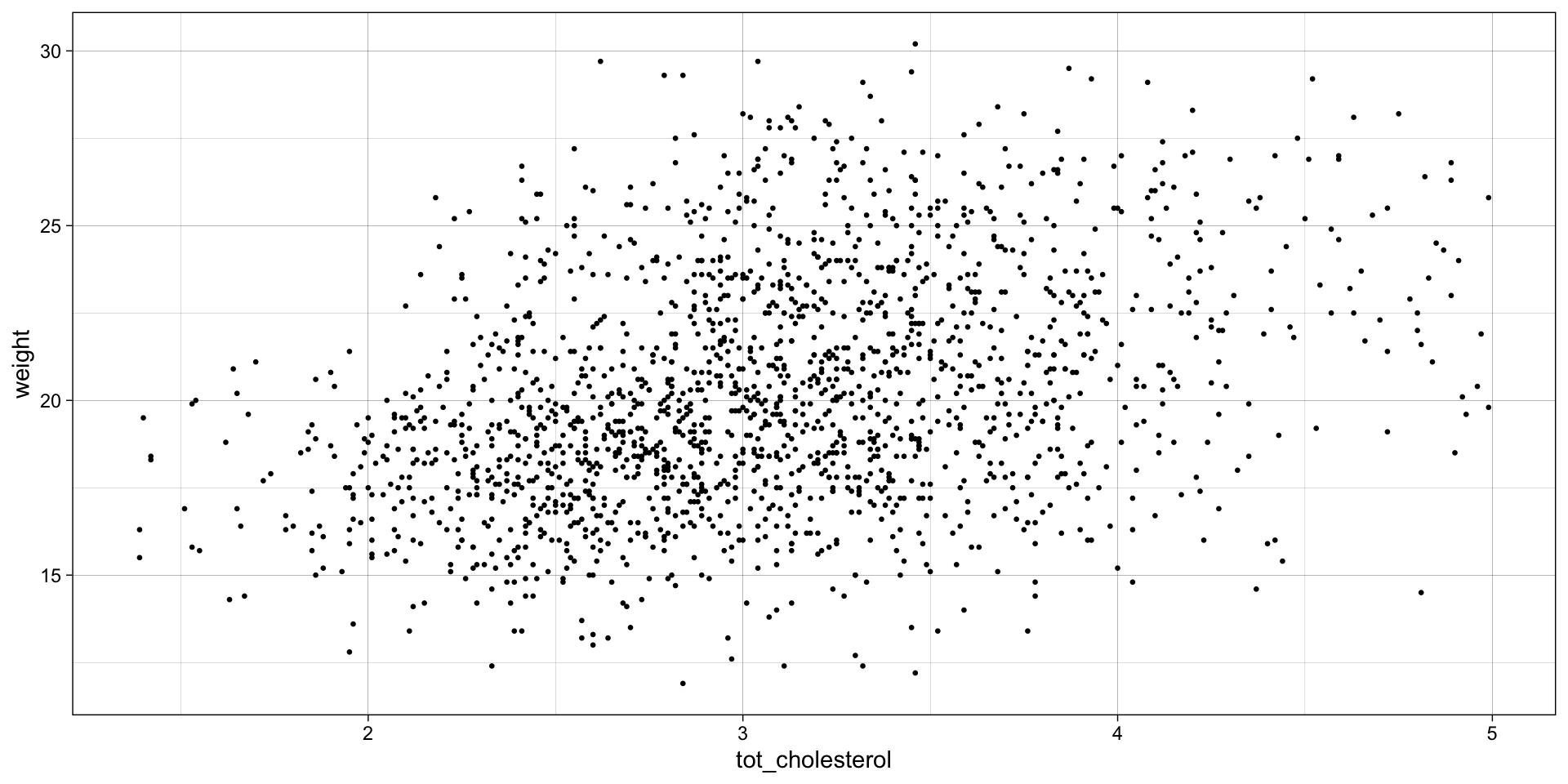
relationship between \(weight\) and \(tot\_cholesterol\) by \(sex\)
b |>group_by(sex) |>cor_test(weight, tot_cholesterol, method ="pearson") |>gt()
sex
var1
var2
cor
statistic
p
conf.low
conf.high
method
F
weight
tot_cholesterol
0.10
3.063798
0.002250
0.03678781
0.1667760
Pearson
M
weight
tot_cholesterol
0.12
3.558249
0.000393
0.05323591
0.1827541
Pearson
Appropriate statistical test cheatsheet
Regression
We are going to change our frame work to learn about regression. The nice thing is that everything we learn for regression is applicable to all the tests we just learned.
The simplicity underlying common tests
Most of the common statistical models (t-test, correlation, ANOVA; etc.) are special cases of linear models or a very close approximation. This simplicity means that there is less to learn. It all comes down to:
\(y = a \cdot x + b\)
This needless complexity multiplies when students try to rote learn the parametric assumptions underlying each test separately rather than deducing them from the linear model.
Equation for a line
Remember: \(y = a \cdot x + b\)
OR \(y = b + a \cdot x\)
\(a\) is the SLOPE (2) \(b\) is the y-intercept (1)
The cool thing here is that we can assess and compare our null and alternative hypothesis by learning and examining the model coefficients (namely the slope). Ultimately, we are comparing a complex model (with cholesterol) to a simple model (without cholesterol).
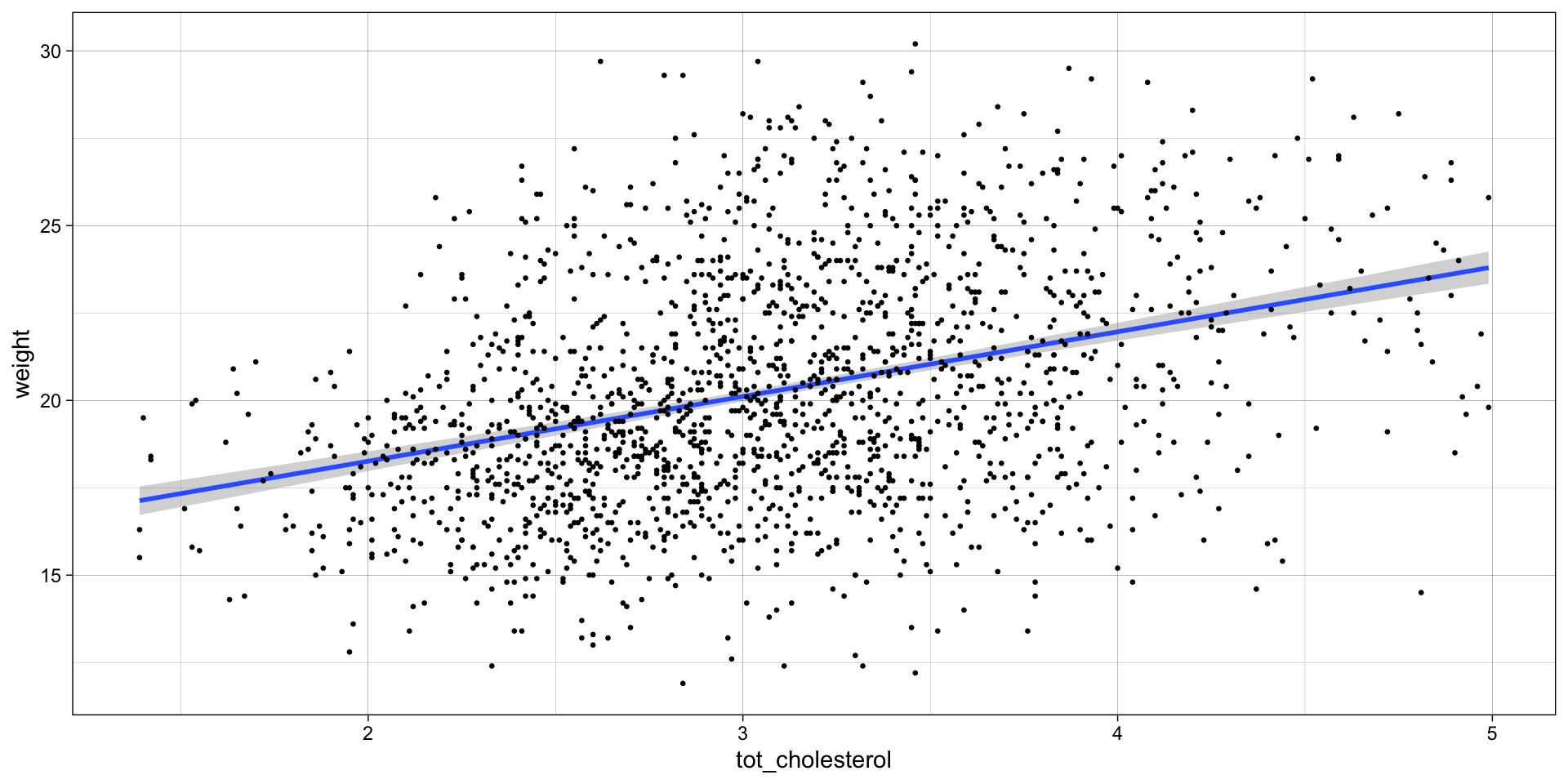
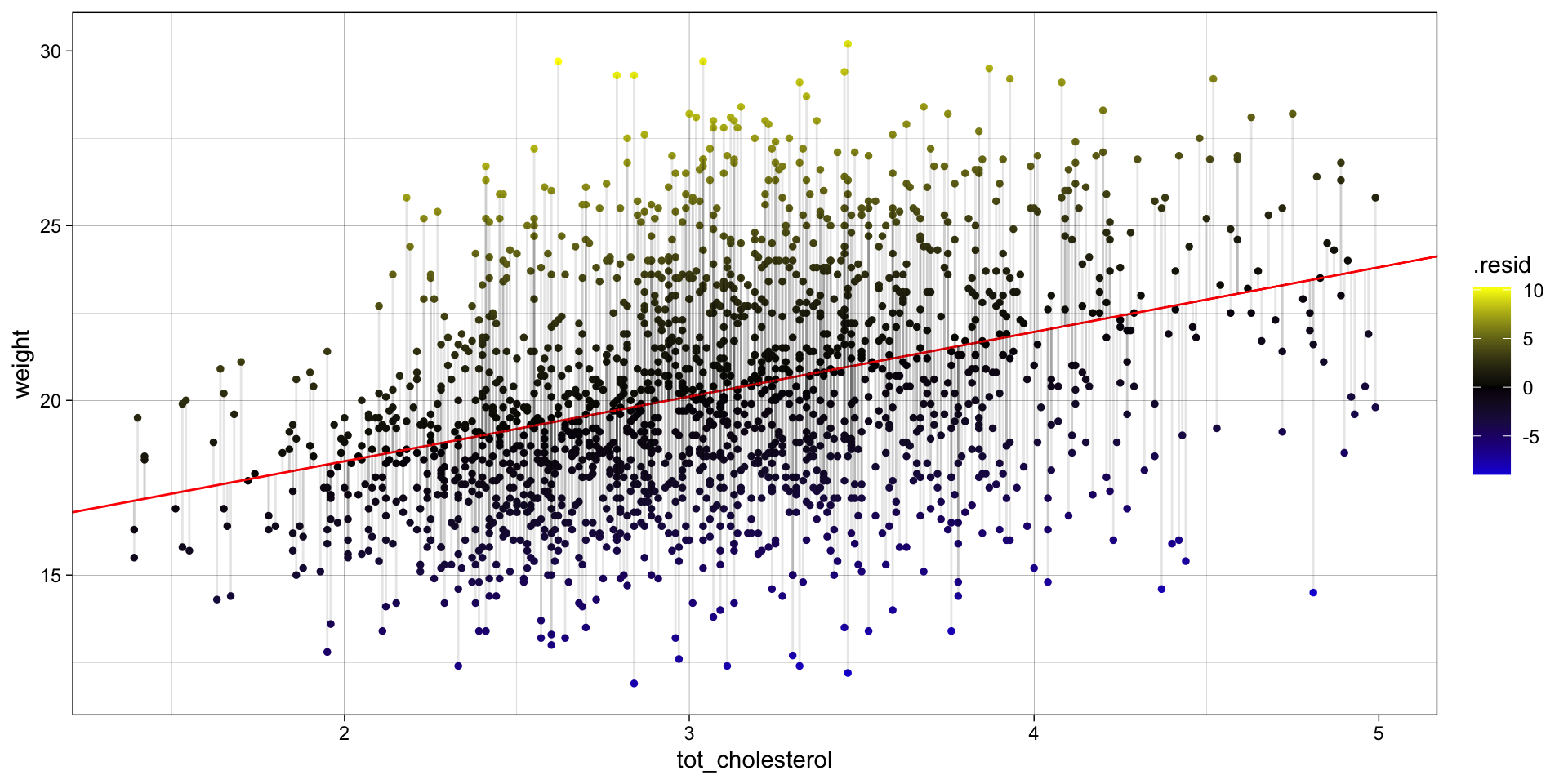
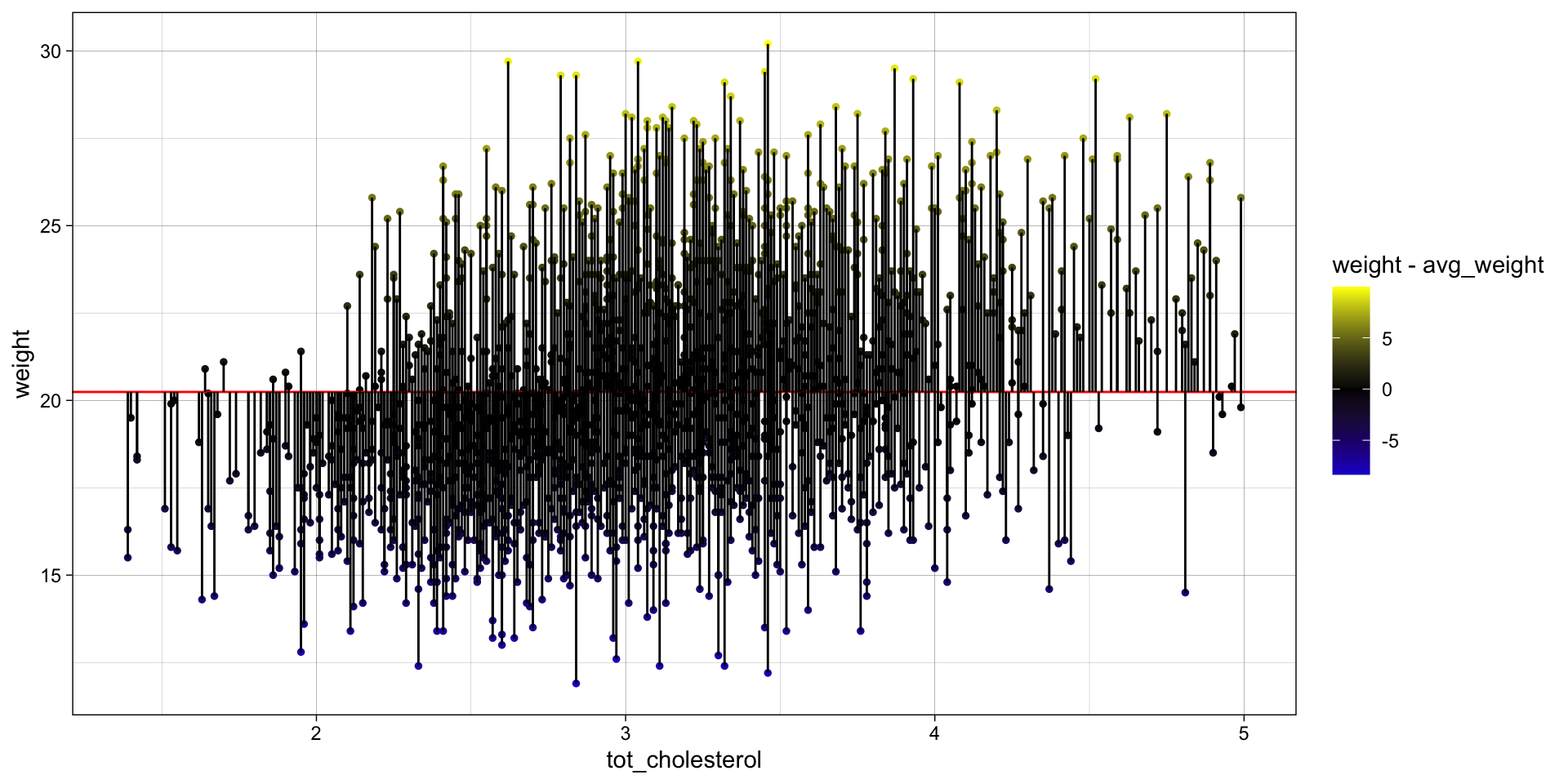
Residuals, \(e\) — the difference between the observed value of the response variable \(y\) and the explanatory value \(\widehat{y}\) is called the residual. Each data point has one residual. Specifically, it is the distance on the y-axis between the observed \(y_{i}\) and the fit line.
\(e = y_{i} - \widehat{y}\)
Residuals with large absolute values indicate the data point is NOT well explained by the model.
STEP 5: Visualize fit and errors
Visualize the residuals OR the error around the fit
\(R^2\) — the coefficient of determination, which is the proportion of the variance in the response variable that is predictable from the explanatory variable(s).
BTW this is the same \(R\) as from the Pearson correlation, just squared:
b |>cor_test(weight, tot_cholesterol, method ="pearson") |>mutate(rsq = cor^2) |>pull(rsq) |>round(2)
cor
0.12
Interpret \(R^2\)
There is a 13% reduction in the variance when we take mouse \(cholesterol\) into account
OR \(cholesterol\) explains 13% of variation in mouse \(weight\)
What is the F-statistic
F-statistic — based on the ratio of two variances: the explained variance (due to the model) and the unexplained variance (residuals).
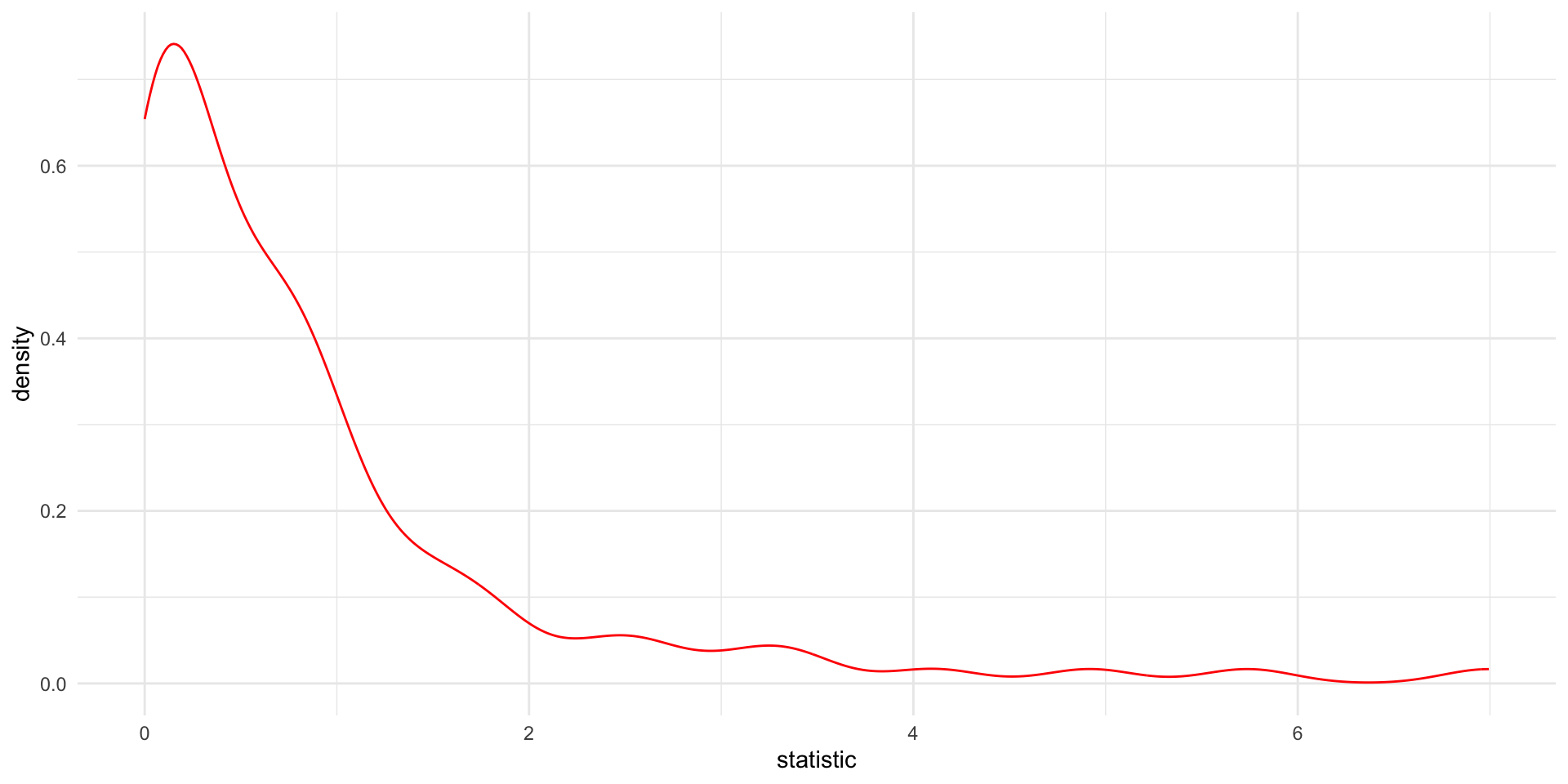
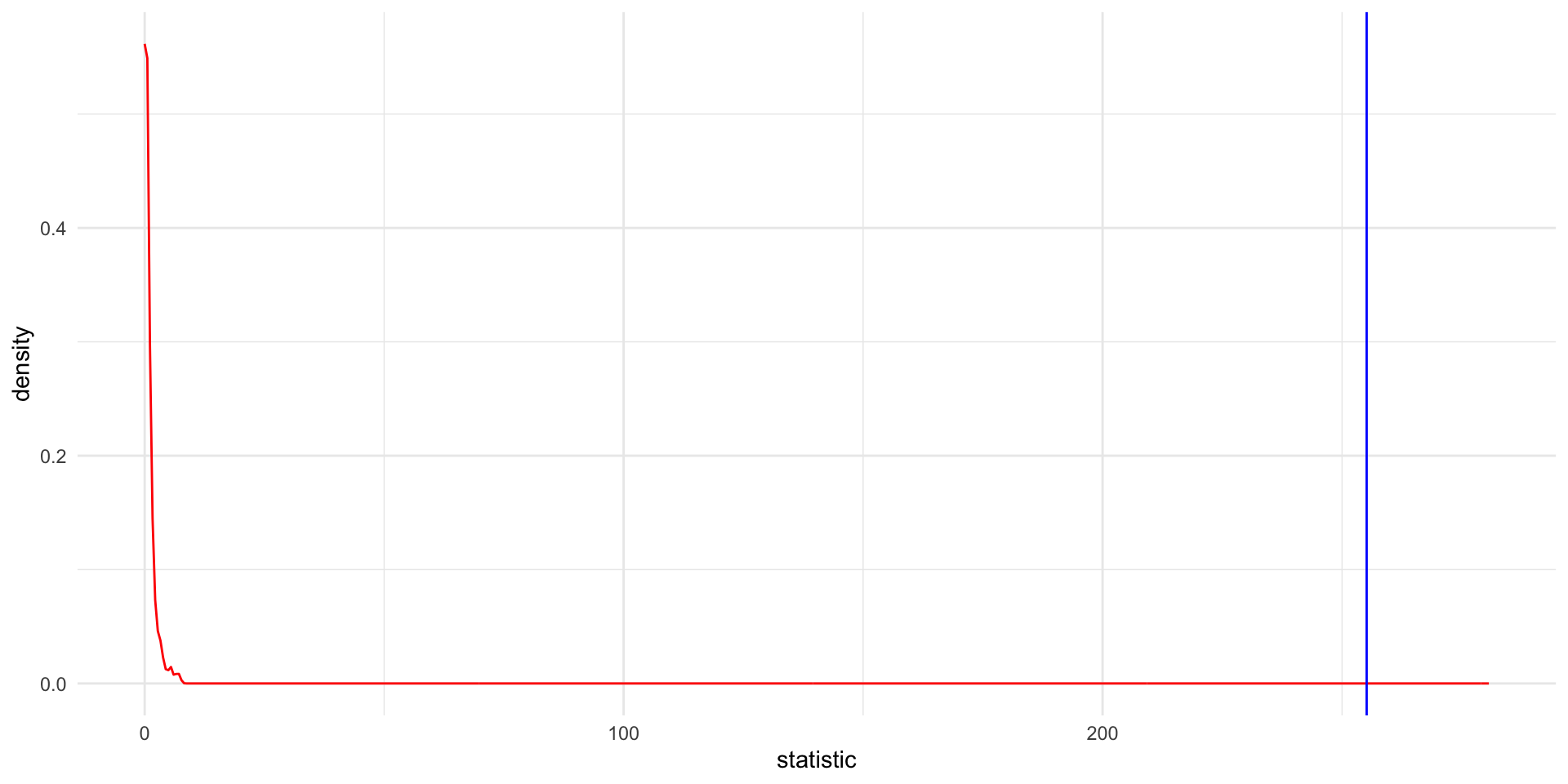
You don’t really need to know what the \(F-statistic\) is unless you want to calculate the p-value. In this case we need to generate a null distribution of \(F-statistic\) values to compare to our observed \(F-statistic\).
Therefore, we will randomize the \(tot_cholesterol\) and \(weight\) and then calculate the \(F-statistic\).
We will do this many many times to generate a null distribution of \(F-statistic\)s.
The p-value will be the probability of obtaining an \(F-statistic\) in the null distribution at least as extreme as our observed \(F-statistic\).
Let’s get started
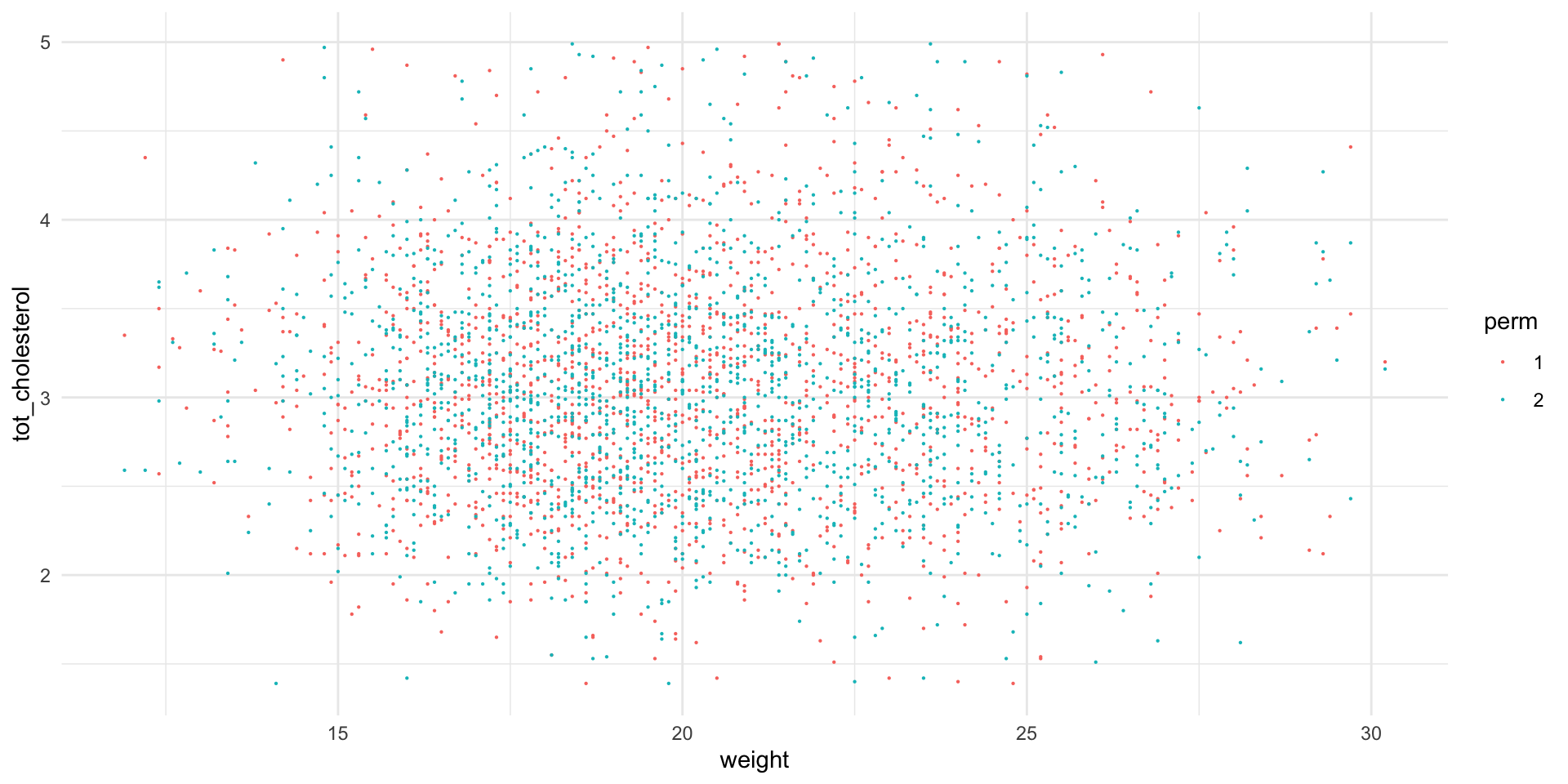
# set up an empty tibble to hold our null distributionfake_biochem <-tribble()# we will perform 100 permutationsmyPerms <-100for (i in1:myPerms) { tmp <-bind_cols( b_WvC[sample(nrow(b_WvC)), "weight"], b_WvC[sample(nrow(b_WvC)), "tot_cholesterol"],"perm"=factor(rep(i, nrow(b_WvC))) ) fake_biochem <-bind_rows(fake_biochem, tmp)rm(tmp)}# let's look at permutations 1 and 2ggplot( fake_biochem |>filter(perm %in%c(1:2)),aes(x = weight, y = tot_cholesterol, color = perm)) +geom_point(size = .1) +theme_minimal()
Let’s get started
Run 100 linear models!
Now we will calculate and extract linear model results for each permutation individually using nest, mutate, and map functions