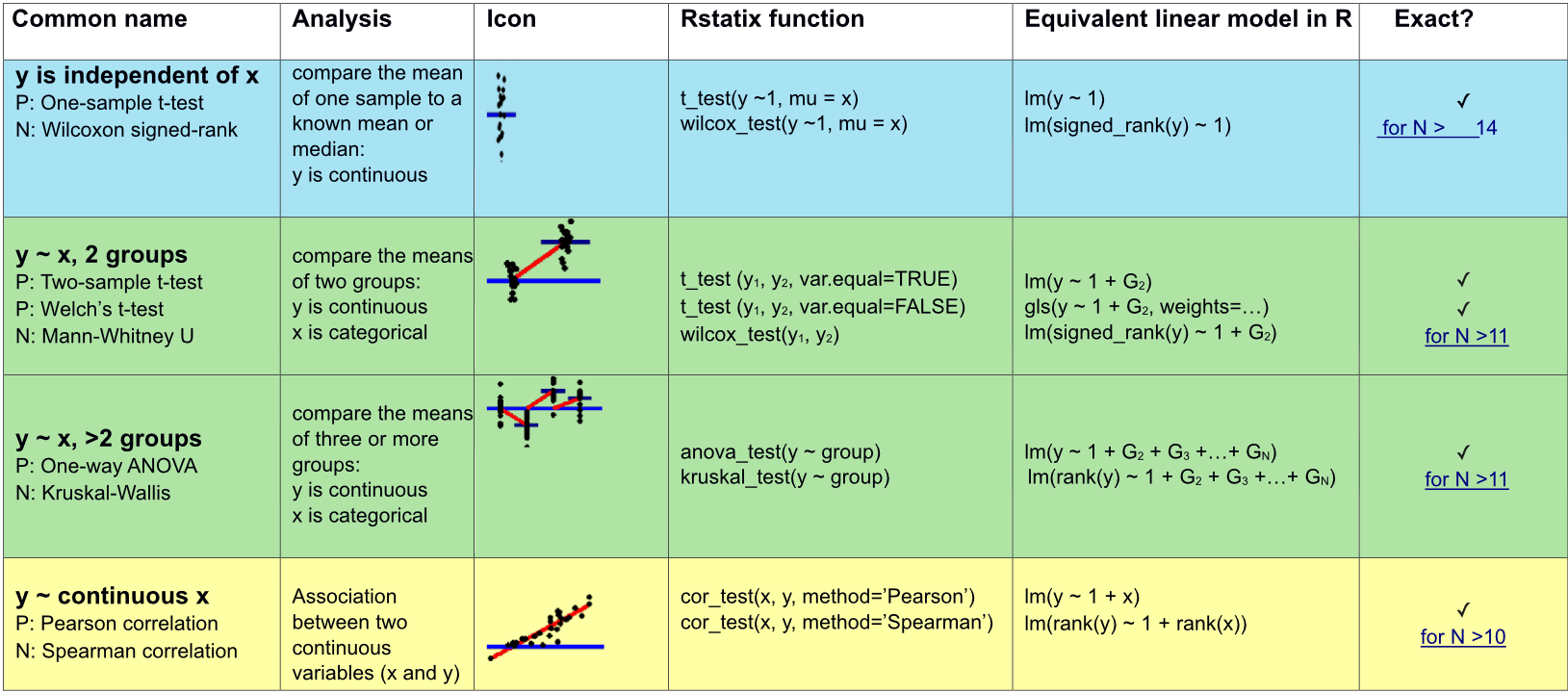
Identify and Perform the proper statistical test for data type/comparison
Calculate and Interpret p-values
Hypothesis testing definitions
Hypothesis testing is a statistical analysis that uses sample data to assess two mutually exclusive theories about the properties of a population. Statisticians call these theories the null hypothesis and the alternative hypothesis. A hypothesis test assesses your sample statistic and factors in an estimate of the sample error to determine which hypothesis the data support.
When you can reject the null hypothesis, the results are statistically significant, and your data support the theory that an effect exists at the population level.
A legal analogy: Guilty or not guilty?
The statistical concept of ‘significant’ vs. ‘not significant’ can be understood by comparing to the legal concept of ‘guilty’ vs. ‘not guilty’.
In the American legal system (and much of the world) a criminal defendant is presumed innocent until proven guilty. If the evidence proves the defendant guilty beyond a reasonable doubt, the verdict is ‘guilty’. Otherwise the verdict is ‘not guilty’. In some countries, this verdict is ‘not proven’, which is a better description. A ‘not guilty’ verdict does not mean the judge or jury concluded that the defendant is innocent – it just means that the evidence was not strong enough to persuade the judge or jury that the defendant was guilty.
In statistical hypothesis testing, you start with the null hypothesis (usually that there is no difference between groups). If the evidence produces a small enough P value, you reject that null hypothesis, and conclude that the difference is real. If the P value is higher than your threshold (usually 0.05), you don’t reject the null hypothesis. This doesn’t mean the evidence convinced you that the treatment had no effect, only that the evidence was not persuasive enough to convince you that there is an effect.
Definitions
Effect — the difference between the population value and the null hypothesis value. The effect is also known as population effect or the difference. Typically, you do not know the size of the actual effect. However, you can use a hypothesis test to help you determine whether an effect exists and to estimate its size.
Null Hypothesis or \(\mathcal{H}_0\) — one of two mutually exclusive theories about the properties of the population in hypothesis testing. Typically, the null hypothesis states that there is no effect (i.e., the effect size equals zero).
Alternative Hypothesis or \(\mathcal{H}_1\) — the other theory about the properties of the population in hypothesis testing. Typically, the alternative hypothesis states that a population parameter does not equal the null hypothesis value. In other words, there is a non-zero effect. If your sample contains sufficient evidence, you can reject the null and favor the alternative hypothesis.
Definitions cont.
P-values — the probability of obtaining test results at least as extreme as the results actually observed, under the assumption that the null hypothesis is correct. Lower p-values represent stronger evidence against the null. P-values in conjunction with the significance level determines whether your data favor the null or alternative hypothesis.
p = 0.03
There is a 3% chance of observing a difference as large as you observed even if the two population means are identical (the null hypothesis is true).
or
Random sampling from identical populations would lead to a difference smaller than you observed in 97% of experiments, and larger than you observed in 3% of experiments.
NOT
There is a 97% chance that the difference you observed reflects a real difference between populations, and a 3% chance that the difference is due to chance.
Significance Level or \(a\) — an evidentiary standard set before the study. It is the probability that you say there is an effect when there is no effect (the probability of rejecting the null hypothesis given that it is true). Lower significance levels indicate that you require stronger evidence before you will reject the null.It is usually set at or below .05.
Variables definitions
Random variables
Response Variable ( y - aka dependent or outcome variable): this variable is predicted or its variation is explained by the explanatory variable. In an experiment, this is the outcome that is measured following manipulation of the explanatory variable.
Explanatory Variable ( x - aka independent or predictor variable): explains variations in the response variable. In an experiment, it is manipulated by the researcher.
Null hypothesis testing
Examine and specify the variable(s)
Declare null hypothesis \(\mathcal{H}_0\)
Calculate test-statistic, exact p-value
calculating empirical p-value (alternative to 3):
Generate and visualize data reflecting null-distribution
Calculate the frequency of your observation vs all null distribution values
Parametric vs Nonparametric tests
Parametric tests are suitable for normally distributed data.
Nonparametric tests are suitable for any continuous data. Though these tests have their own sets of assumption, you can think of Nonparametric tests as the ranked versions of the corresponding parametric tests.
*With many samples (>20) then lack of normality assumption is not a concern due to the central limit theorem. AND shapiro_test() is too sensitive with large number of observations.
Two changes
We are going to use ggpubr rather than ggplot2 - Don’t tell Jay ;)
It has great visualization for the stats on the plots.
Different syntax!!
must use double quotes around “variable names”
Due to reviewer #3, we will pivot to a more “physiologically relevant” data set biochem that consists of mouse measurements.
# we are reading the data directly from the internetbiochem <-read_tsv("http://mtweb.cs.ucl.ac.uk/HSMICE/PHENOTYPES/Biochemistry.txt",show_col_types =FALSE) |> janitor::clean_names()# simplify names a bit morecolnames(biochem) <-gsub(pattern ="biochem_",replacement ="",colnames(biochem))# we are going to simplify this a bit and only keep some columnskeep <-colnames(biochem)[c(1, 6, 9, 14, 15, 24:28)]biochem <- biochem[, keep]# get weights for each individual mouse# careful: did not come with column namesweight <-read_tsv("http://mtweb.cs.ucl.ac.uk/HSMICE/PHENOTYPES/weight",col_names = F,show_col_types =FALSE)# add column namescolnames(weight) <-c("subject_name", "weight")# add weight to biochem table and get rid of NAs# rename gender to sexb <-inner_join(biochem, weight, by ="subject_name") |>na.omit() |>rename(sex = gender)
Warning: `geom_vline()`: Ignoring `mapping` because `xintercept` was
provided.
Warning: `geom_vline()`: Ignoring `data` because `xintercept` was
provided.
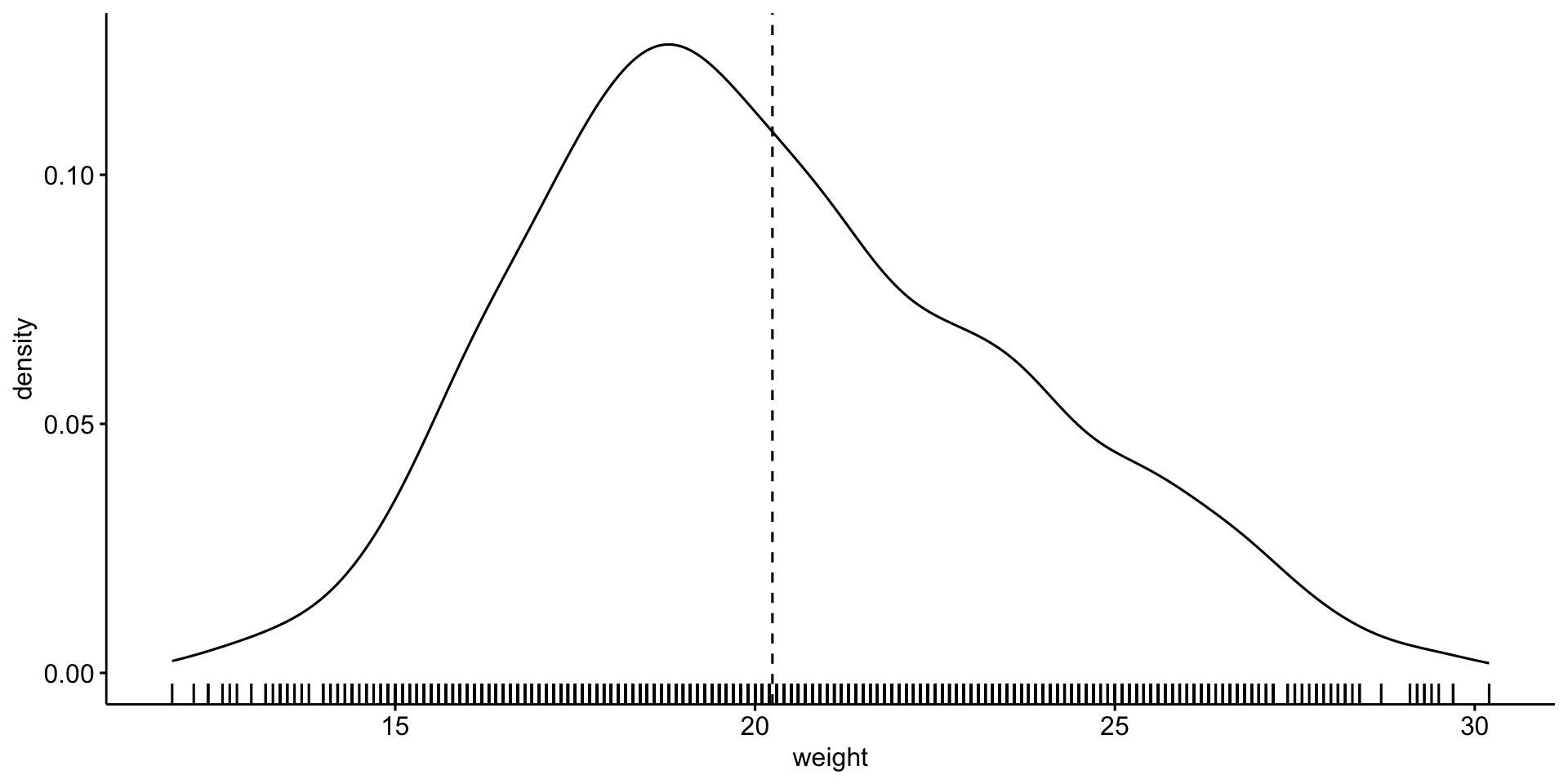
let’s see some summary stats
b |>get_summary_stats( weight,type ="common",show =c("mean", "median", "sd") )
# A tibble: 1 × 5
variable n mean median sd
<fct> <dbl> <dbl> <dbl> <dbl>
1 weight 1782 20.2 19.8 3.34
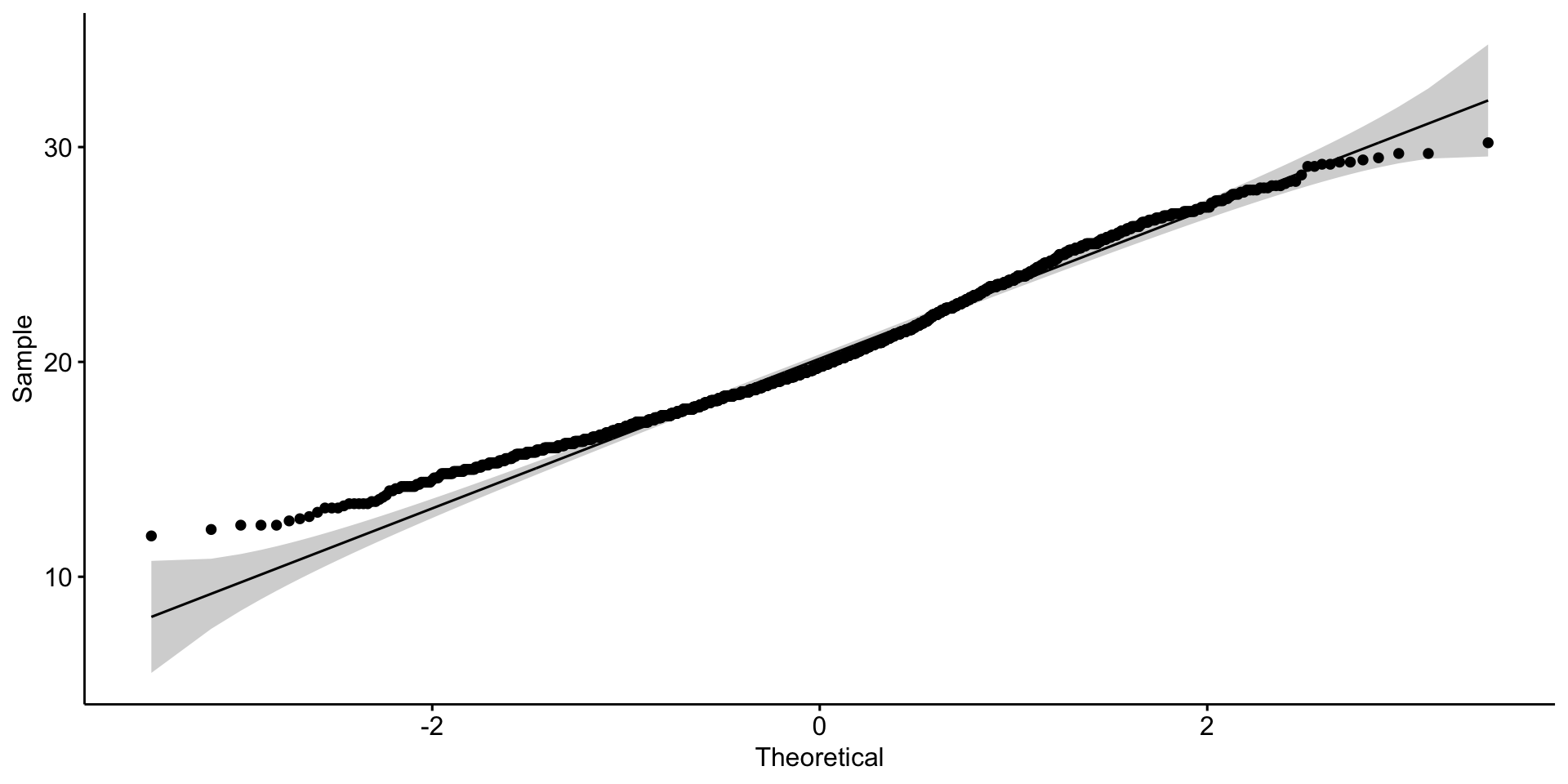
Is it normally distributed?
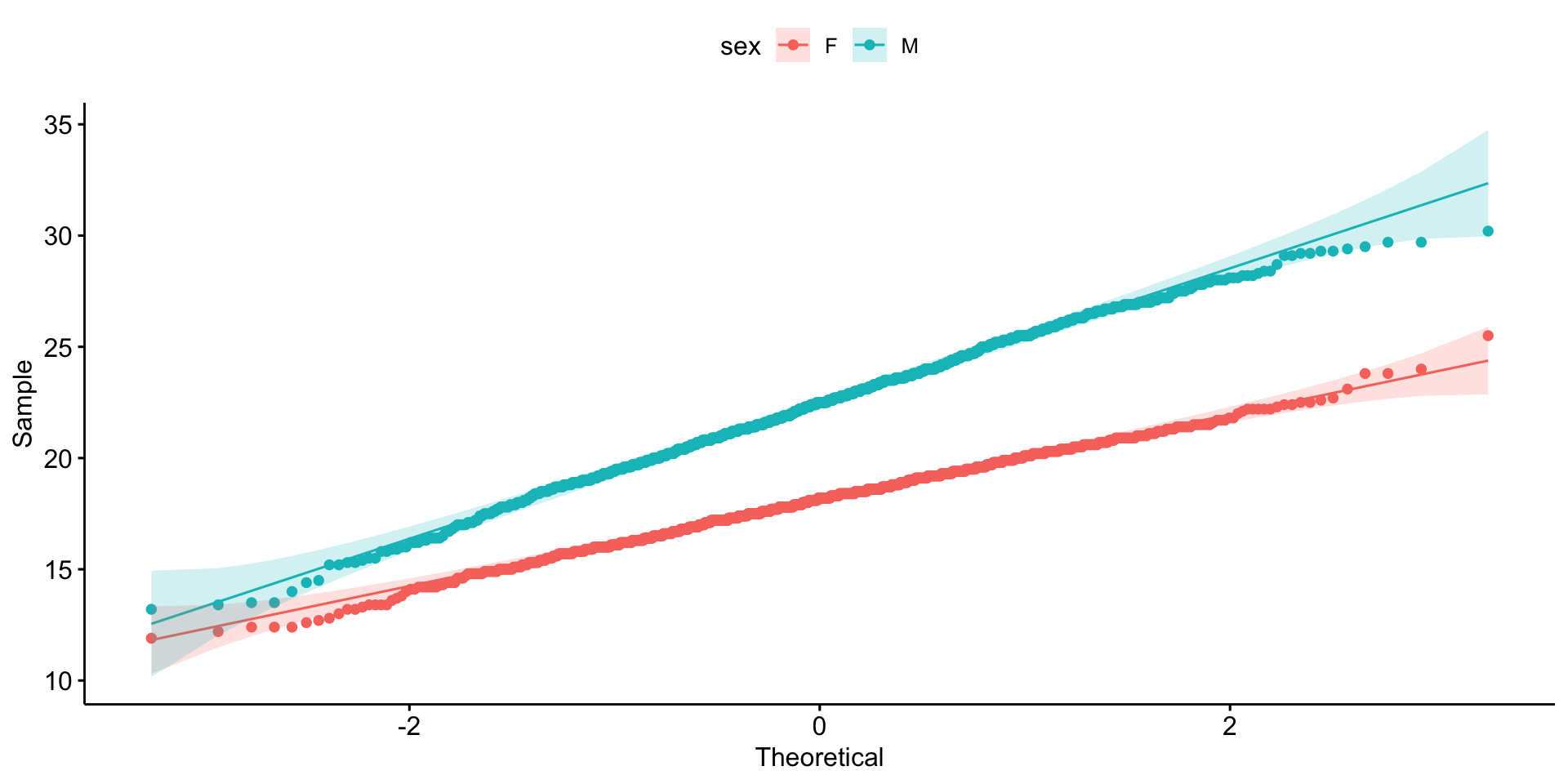
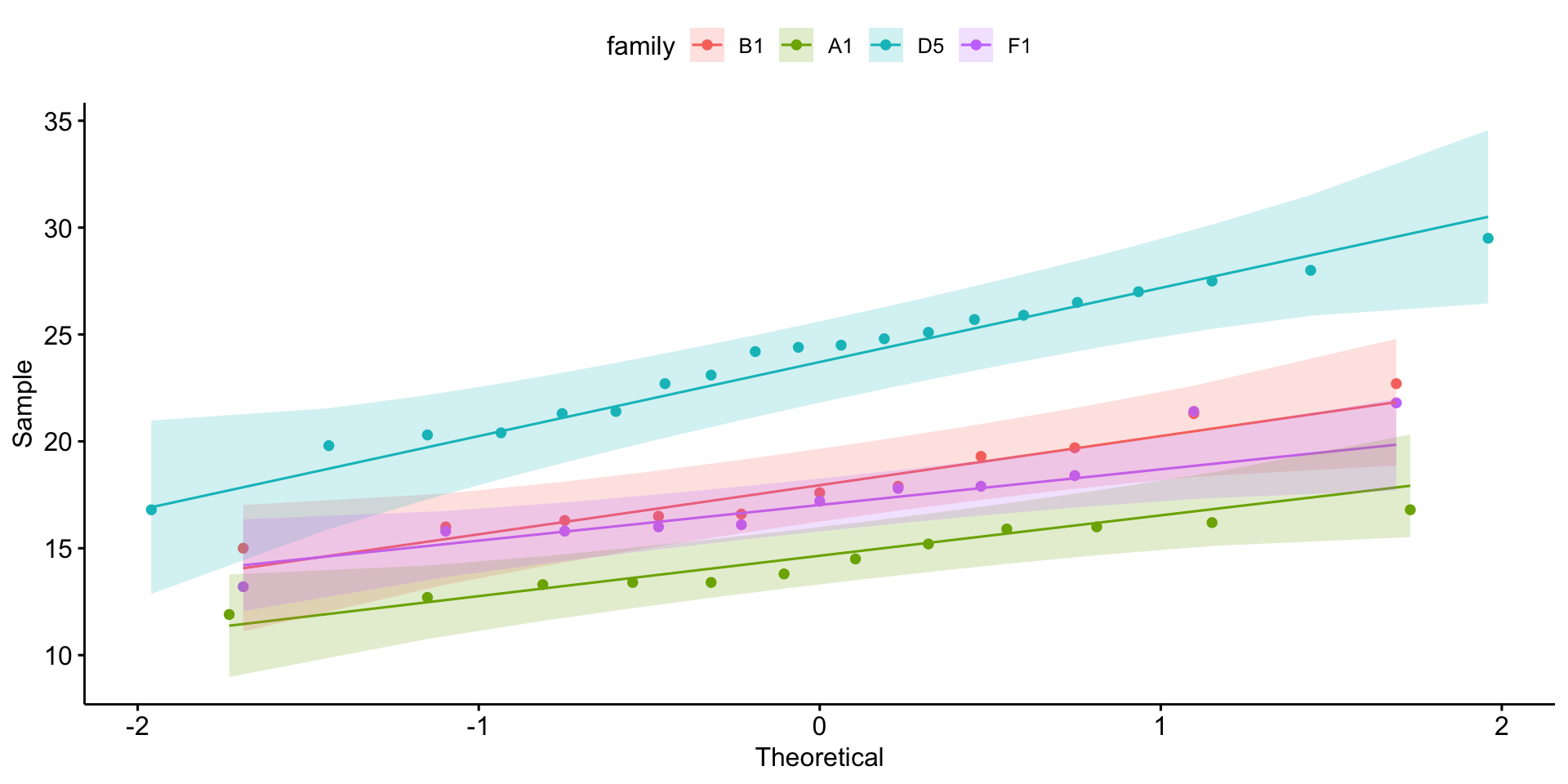
ggqqplot(data = b,x ="weight")
Looks reasonable
b |>shapiro_test(weight)
# A tibble: 1 × 3
variable statistic p
<chr> <dbl> <dbl>
1 weight 0.984 3.47e-13
Yikes!
No easy answers…gotta make a call. We’ll try both.
2. Declare null hypothesis \(\mathcal{H}_0\)
Since this is a one-way test, we don’t need to worry if the groups have equal variance (only 1 group). But, we need a standard to compare against. I asked google, how much does a mouse weigh in grams?
Answer: 20-35 g, I’m going with \(27.5 g\) as our standard.
\(\mathcal{H}_0\) is that the mean of mouse \(weight\) can be explained by \(27.5\)
\(weight\) is the response variable
\(27.5\) is the explanatory variable
3. Calculate test-statistic, exact p-value
Nonparametric test:
x <-27.5# standard from googleb |>wilcox_test(weight ~1, mu = x) |>gt()
.y.
group1
group2
n
statistic
p
weight
1
null model
1782
2084
1.62e-290
Parametric test:
x <-27.5# standard from googleb |>t_test(weight ~1, mu = x) |>gt()
.y.
group1
group2
n
statistic
df
p
weight
1
null model
1782
-91.85587
1781
0
P values are well below 0.05
\(\mathcal{H}_0\) is that the mean of mouse \(weight\) can be explained by \(27.5\) is NOT WELL SUPPORTED
So \(27.5 g\) not able to describe weight
Not surprising since our mean mouse weight is 20.2. Don’t believe everything you read on the internet.
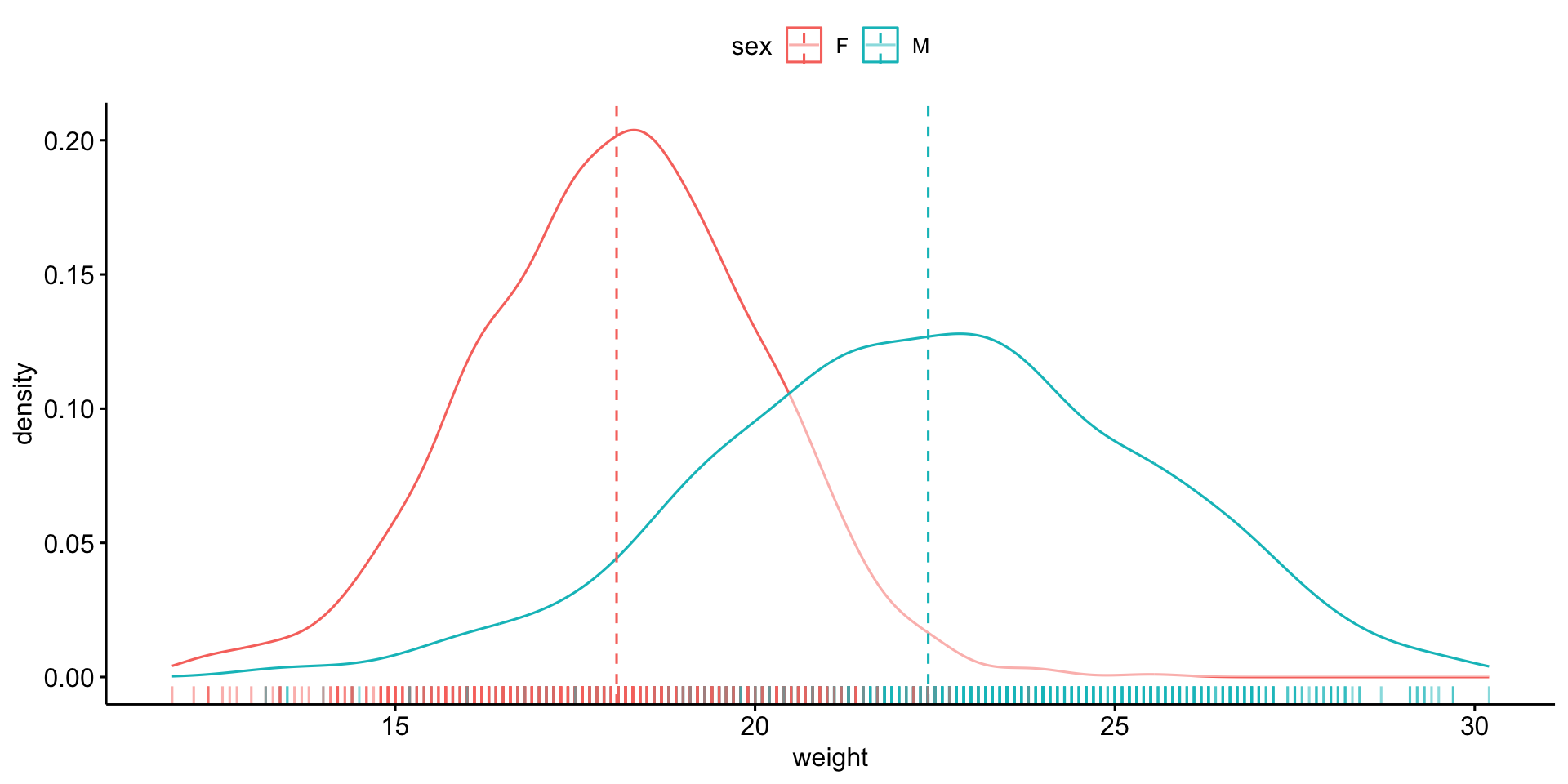
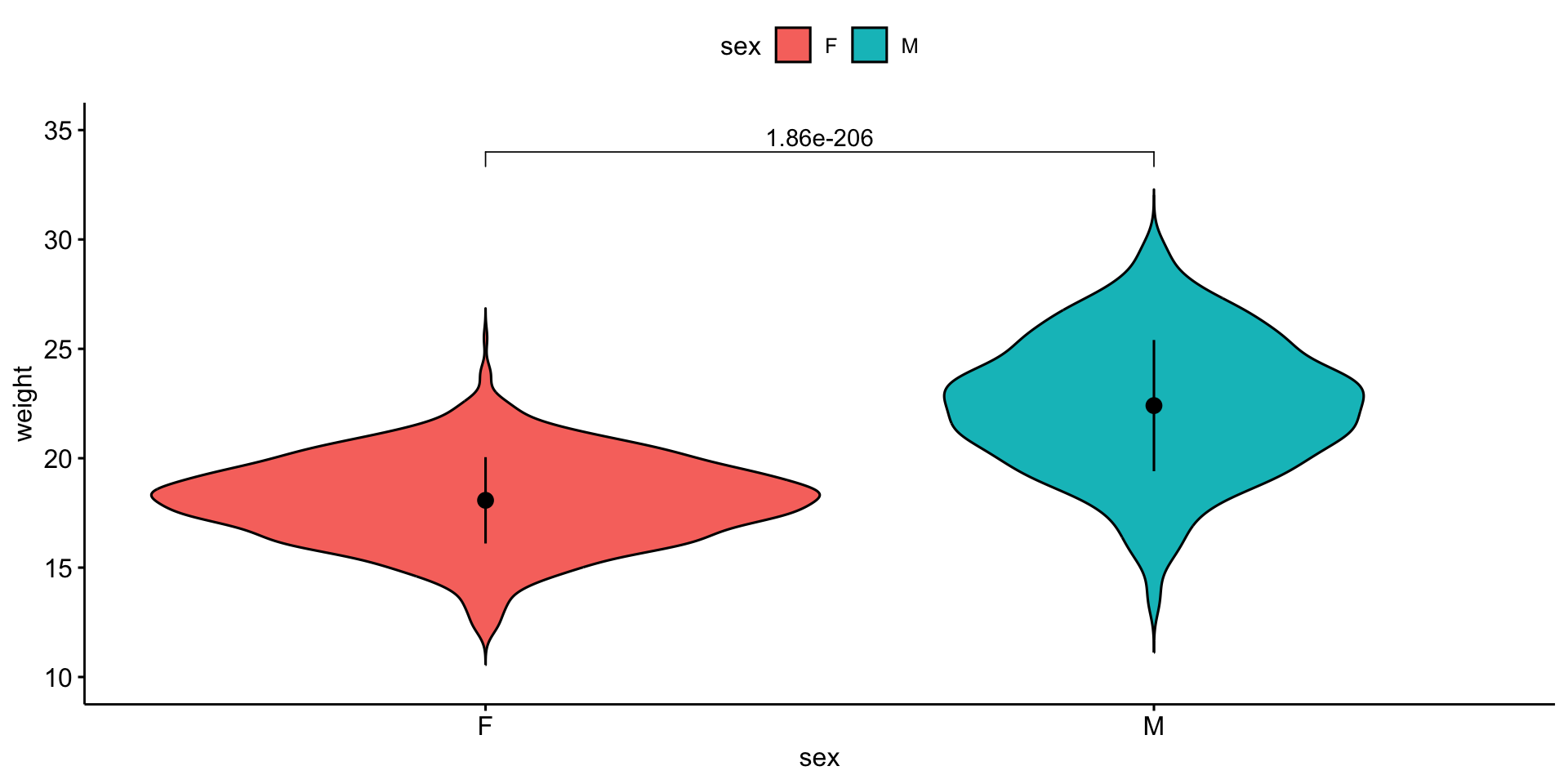
Compare mean of two groups
\(y\) is independent of \(x\)
\(y\) is continuous
\(x\) is categorical with 2 groups (factor w/2 levels)
The T-Distribution, also known as Student’s t-distribution, gets its name from William Sealy Gosset who first published it in English in 1908 in the scientific journal Biometrika using his pseudonym “Student” because his employer preferred staff to use pen names when publishing scientific papers instead of their real name, so he used the name “Student” to hide his identity.
# i have pre-selected some families to comparemyfams <-c("B1.5:E1.4(4) B1.5:A1.4(5)","F1.3:A1.2(3) F1.3:E2.2(3)","A1.3:D1.2(3) A1.3:H1.2(3)","D5.4:G2.3(4) D5.4:C4.3(4)")# only keep the familys in myfamsbfam <- b |>filter(family %in% myfams) |>droplevels()# simplify family names and make factorbfam$family <-gsub(pattern ="\\..*", replacement ="", x = bfam$family) |>as.factor()# make B1 the reference (most similar to overall mean)bfam$family <-relevel(x = bfam$family, ref ="B1")
Visualize the variable(s)
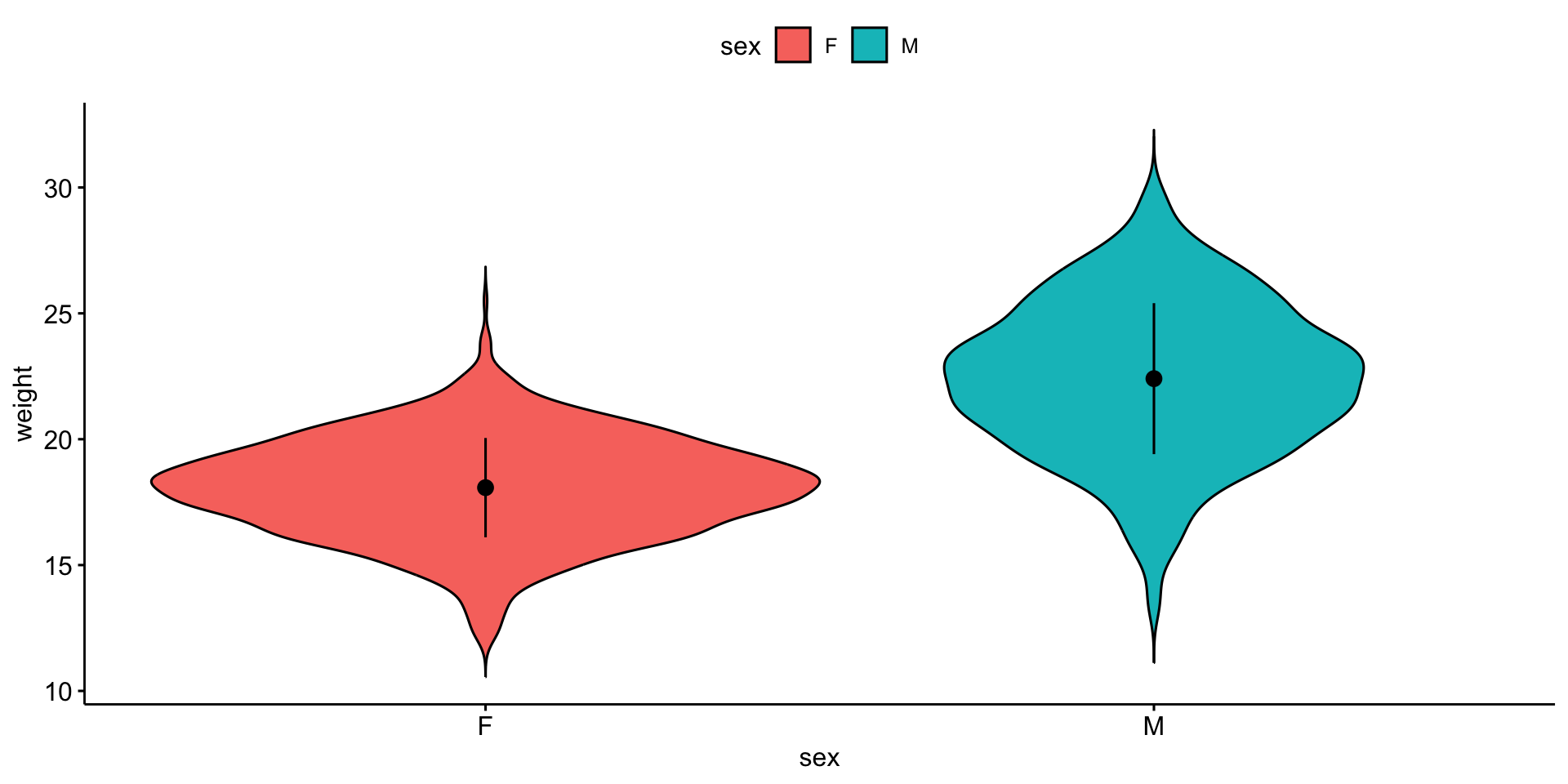
I want the response variable on the \(y\) axis and the explanatory variable on the \(x\) axis.
\(\mathcal{H}_0\) is that \(family\) cannot explain \(weight\)
3. Calculate test-statistic, exact p-value
Parametric test:
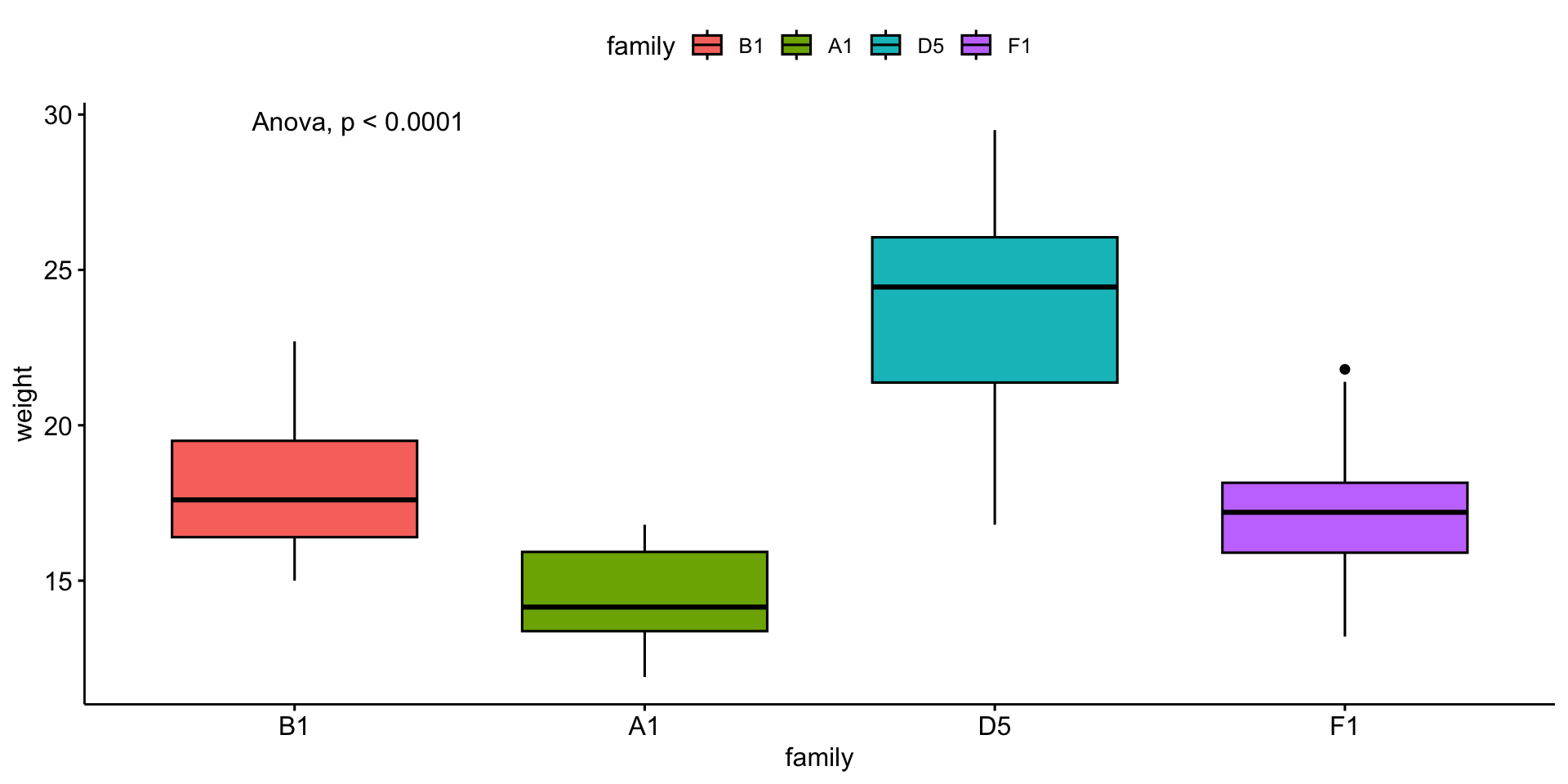
bfam |>anova_test(weight ~ family) |>gt()
Effect
DFn
DFd
F
p
p<.05
ges
family
3
50
37.514
7.62e-13
*
0.692
Nonparametric test:
bfam |>kruskal_test(weight ~ family) |>gt()
.y.
n
statistic
df
p
method
weight
54
37.07763
3
4.43e-08
Kruskal-Wallis
P values are well below 0.05
\(\mathcal{H}_0\) is that \(family\) cannot explain \(weight\) is NOT WELL SUPPORTED
\(family\) can explain \(weight\)
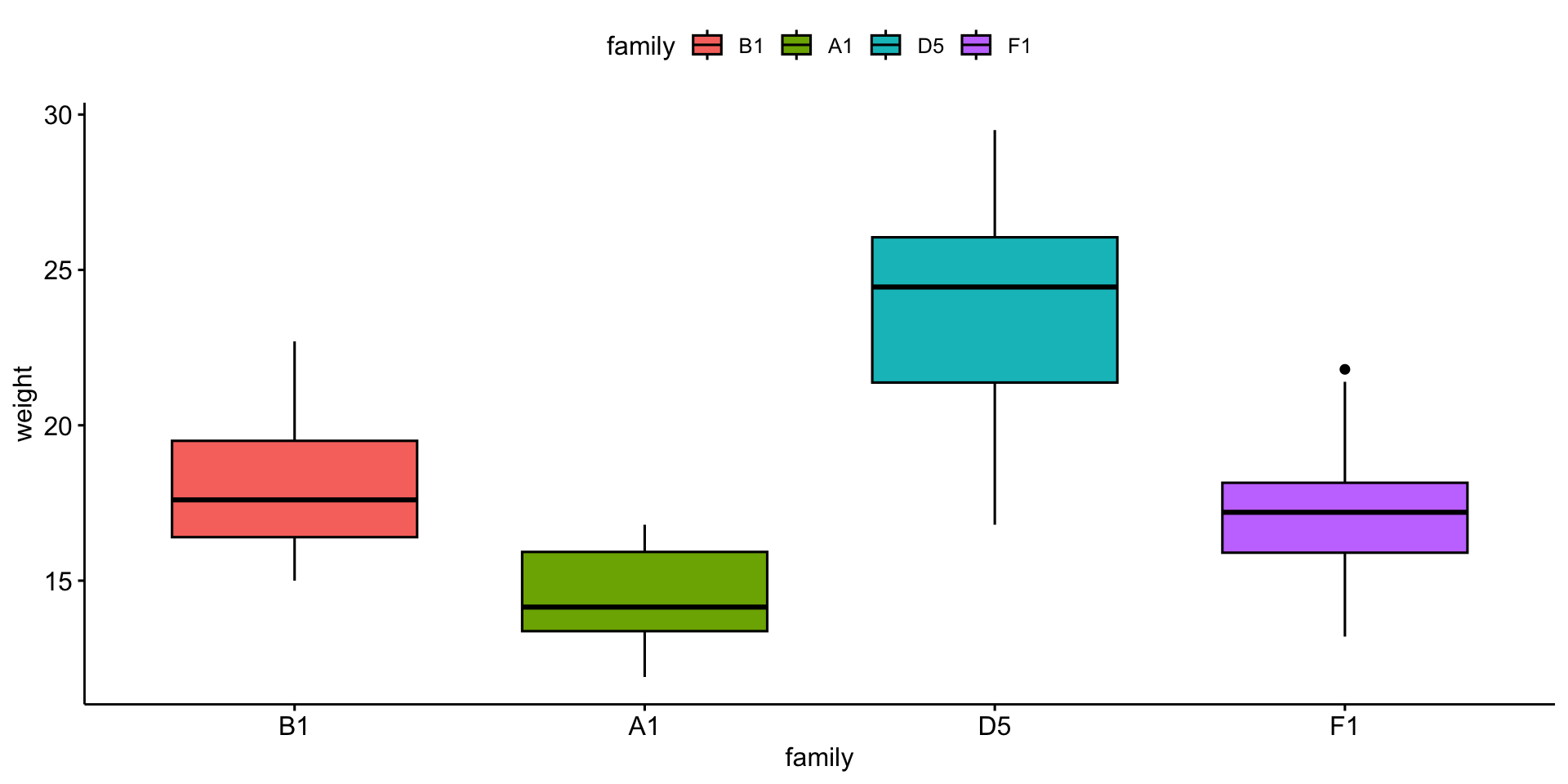
Visualize the result
# save statistical test resultstatres <- bfam |>anova_test(weight ~ sex)ggboxplot(data = bfam,y ="weight",x ="family",fill ="family") +stat_anova_test()
Visualize the result
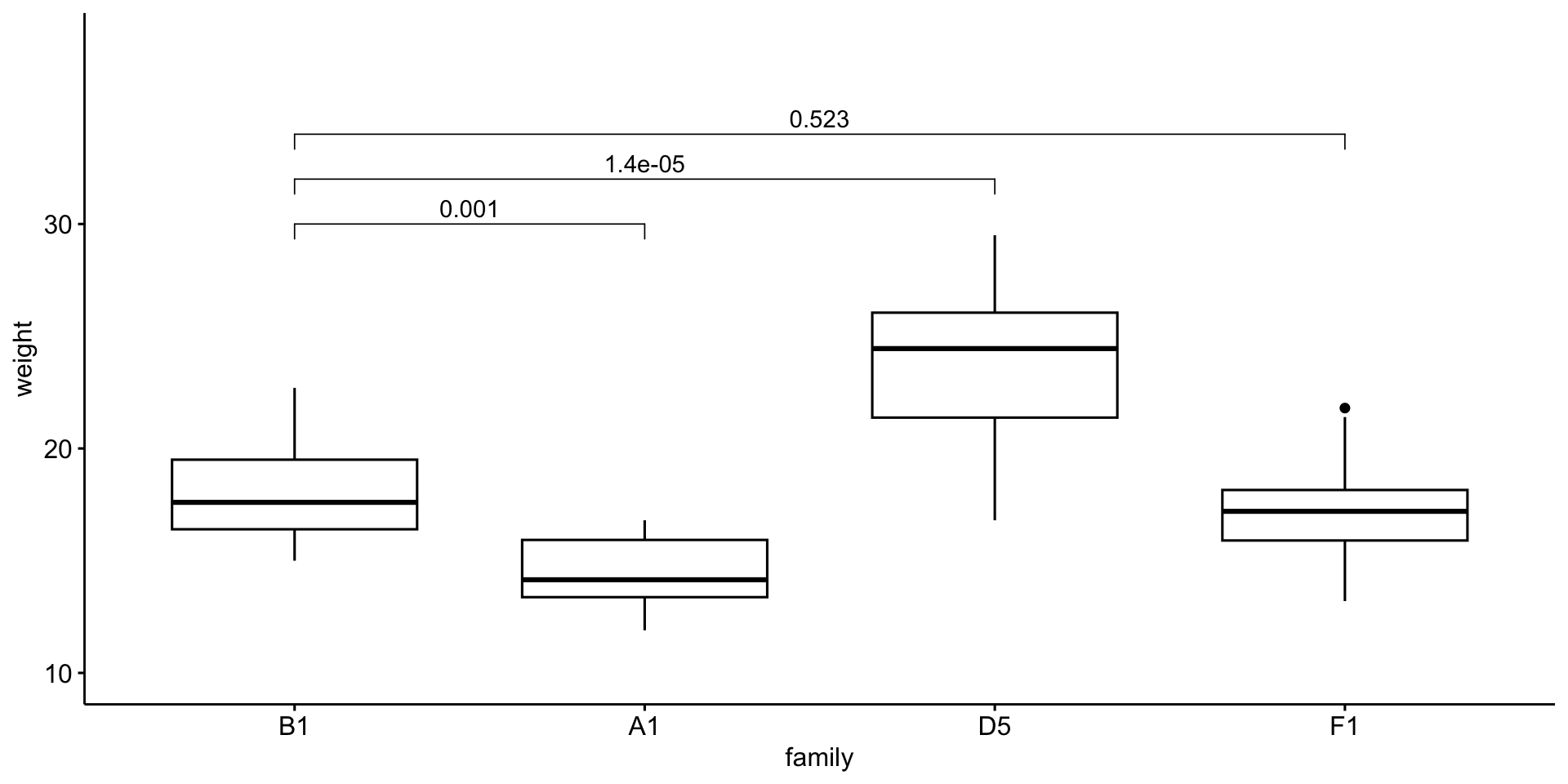
Multiple pairwise comparisons
Quick aside
# save statistical test resultpairwise <- bfam |>t_test(weight ~ family, ref.group ="B1")ggboxplot(bfam, x ="family", y ="weight", fill ="weight", ) +stat_pvalue_manual( pairwise,label ="p.adj",y.position =c(30, 32, 34) ) +ylim(10, 38)
Notice that not all pairwise differences are significant, yet the ANOVA is significant.
Multiple pairwise comparisons
Warning: The following aesthetics were dropped during statistical
transformation: fill.
ℹ This can happen when ggplot fails to infer the correct
grouping structure in the data.
ℹ Did you forget to specify a `group` aesthetic or to
convert a numerical variable into a factor?