Visualize numerical single-cell data by creating a histogram, density plot, violin plots, or boxplots. When plotting V(D)J data, values can be plotted separately for each chain or summarized and plotted for each cell.
Usage
plot_histogram(
input,
data_col,
cluster_col = NULL,
group_col = NULL,
method = "histogram",
top = NULL,
other_label = "other",
units = "frequency",
plot_colors = NULL,
plot_lvls = NULL,
trans = "identity",
panel_nrow = NULL,
panel_scales = "fixed",
na_color = "grey80",
n_label = NULL,
label_params = list(),
...,
per_chain = FALSE,
chain = NULL,
chain_col = global$chain_col,
summary_fn = mean,
sep = global$sep
)
plot_violin(
input,
data_col,
cluster_col = NULL,
group_col = NULL,
method = "violin",
top = NULL,
other_label = "other",
plot_colors = NULL,
plot_lvls = NULL,
trans = "identity",
panel_nrow = NULL,
panel_scales = "free_x",
na_color = "grey80",
n_label = NULL,
label_params = list(),
...,
per_chain = FALSE,
chain = NULL,
chain_col = global$chain_col,
summary_fn = mean,
sep = global$sep
)Arguments
- input
Single cell object or data.frame, if a data.frame is provided, cell barcodes should be stored as row names.
- data_col
meta.data column containing data to plot
- cluster_col
meta.data column containing cluster IDs to use for grouping cells for plotting
- group_col
meta.data column to use for grouping clusters into separate panels
- method
Method to use for plotting, possible values include, 'histogram', 'density', 'boxplot', or 'violin'
- top
To only show the top cell groups, provide one of the following, all other cells will be labeled using the value provided to the
other_labelargument. IfNULLthis will be automatically set.Integer specifying the number of top groups to show
Vector specifying the names of cell groups to show
- other_label
Label to use for 'other' cells when
topis specified, ifNULLall cell groups will be shown.- units
Units to use for y-axis when method is 'histogram'. Use 'frequency' to show the number of values or 'percent' to show the percentage of total values.
- plot_colors
Character vector specifying colors to use for cell clusters specified by cluster_col. When cluster_col is
NULL, plot colors can be directly modified with the ggplot2 parameterscolorandfill, e.g.fill = "red",color = "black"- plot_lvls
Character vector containing order to use for plotting cell clusters specified by cluster_col
- trans
Transformation to use when plotting data, e.g. 'log10'. By default values are not transformed, refer to
ggplot2::continuous_scale()for more options.- panel_nrow
The number of rows to use for arranging plot panels
- panel_scales
Should scales for plot panels be fixed or free. This passes a scales specification to
ggplot2::facet_wrap(), can be 'fixed', 'free', 'free_x', or 'free_y'. 'fixed' will cause panels to share the same scales.- na_color
Color to use for missing values. If plotting V(D)J data, cells lacking data will be plotted as
NAs.- n_label
Location on plot where n label should be added, this can be any combination of the following:
'corner', display the total number of cells plotted in the top right corner, the position of the label can be modified by passing
xandyspecifications with thelabel_paramsargument'axis', display the number of cells plotted for each group shown on the x-axis
'legend', display the number of cells plotted for each group shown in the plot legend
'none', do not display the number of cells plotted
- label_params
Named list providing additional parameters to modify n label aesthetics, e.g. list(size = 4, color = "red")
- ...
Additional arguments to pass to ggplot2, e.g. color, fill, size, linetype, etc.
- per_chain
If
TRUEvalues will be plotted for each chain, i.e. each data point represents a chain. IfFALSEvalues will be summarized for each cell usingsummary_fnbefore plotting, i.e. each data point represents a cell.- chain
Chain(s) to use for filtering data before plotting. If NULL data will not be filtered based on chain.
- chain_col
meta.data column containing chains for each cell
- summary_fn
Function to use for summarizing values when
per_chainisFALSE, can be either a function, e.g.mean, or a purrr-style lambda, e.g.~ mean(.x, na.rm = TRUE)where.xrefers to the column. IfNULL, the mean will be calculated.- sep
Separator used for storing per-chain V(D)J data for each cell
See also
summarize_vdj() for more examples on how per-chain data can be
summarized for each cell
Examples
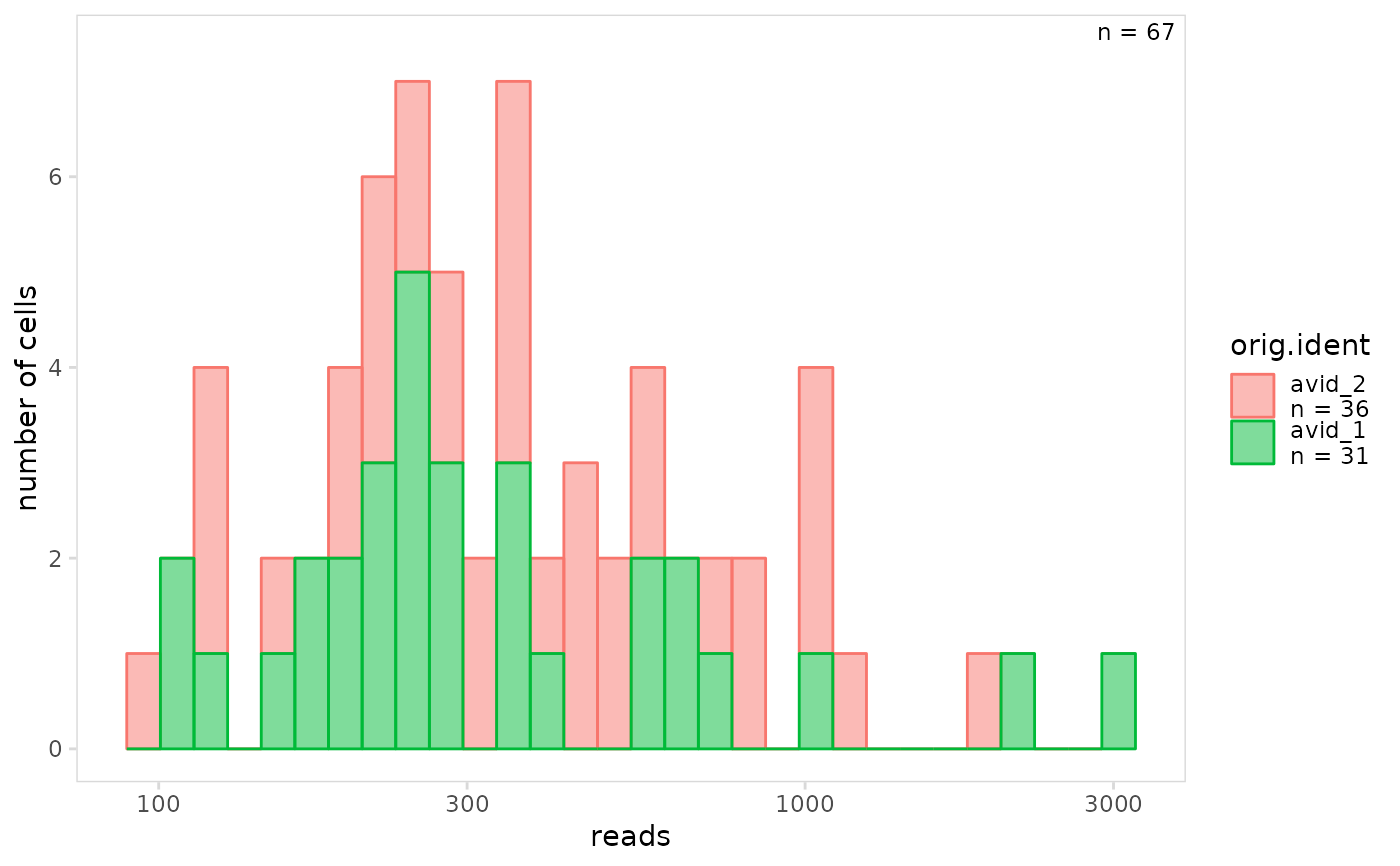
# Create histogram
plot_histogram(
vdj_sce,
data_col = "reads",
cluster_col = "orig.ident",
trans = "log10"
)
#> Warning: Removed 133 rows containing missing values
#> `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
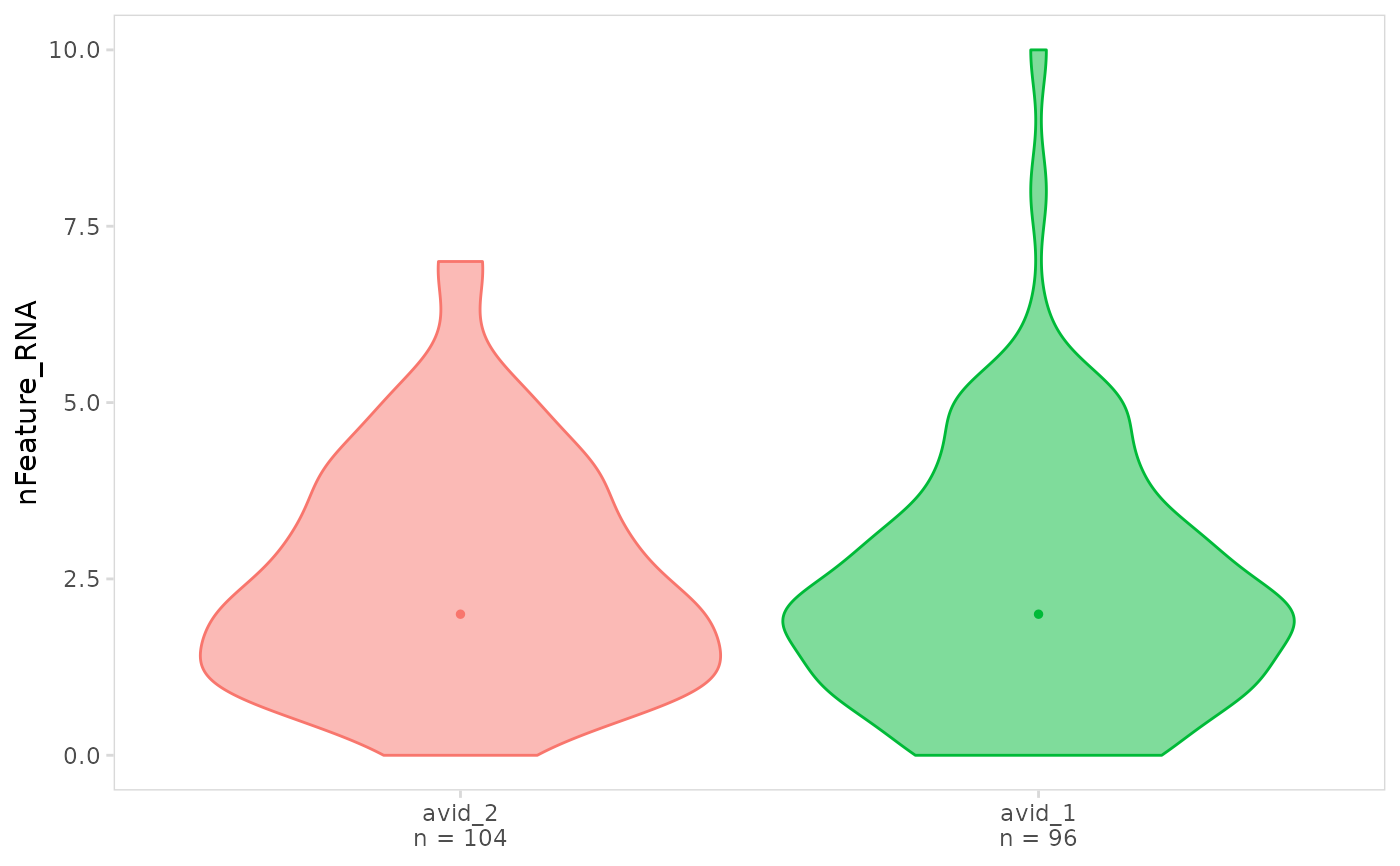
 # Create violin plots
plot_violin(
vdj_sce,
data_col = "nFeature_RNA",
cluster_col = "orig.ident"
)
# Create violin plots
plot_violin(
vdj_sce,
data_col = "nFeature_RNA",
cluster_col = "orig.ident"
)