The Rmarkdown for this class is on github
Goals for this class
- Learn about different types of clustering
- Cluster data using these different approaches
- Learn how to use dimensionality reduction to visualize complex data
Load packages
Download files
Before we get started, let’s download all of the files you will need for the next three classes.
# conditionally download all of the files used in rmarkdown from github
source("https://raw.githubusercontent.com/rnabioco/bmsc-7810-pbda/main/_posts/2023-12-08-class-8-matricies/download_files.R")What is clustering
Clustering is grouping together similar objects or elements. Clustering is a very important part of any type of data analysis.
- Clustering is important for grouping important data togeher - it is what powers those “for you” posts you get when clicking on news articles
- Cluster is also important for biology, it helps us group samples together in RNA-seq or in any experiment where you can get many measurements for samples, cells together in single cell methods
- It can also be used to group together states or districts that are likely to vote in similar ways
Clustering is an unsupervised task - this means that it tries to group together items with no previous knowledge
K - means clustering
I’m loosely following the tutorial here through this section. Click on the above link for a more in-depth discussion.
k-means clustering uses the distance between points as a measure of similarity. The basic idea is that we are adding k points to the data, called centroids that will try to center themselves in the middle of k clusters. This means that the value of k - set by the user, is a very important value to set.
Consider the dataset below
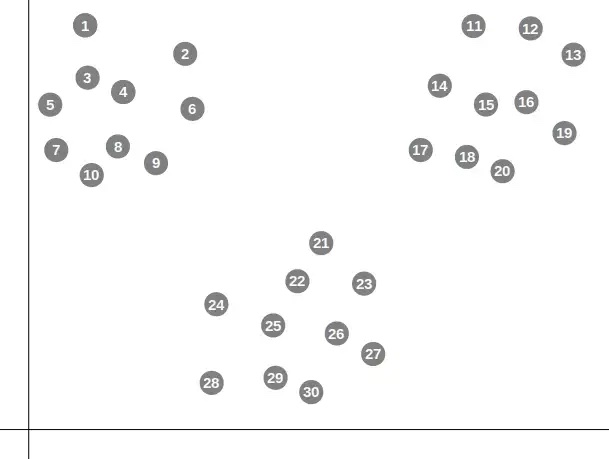
In the figure above you would probably say that there are 3 clear clusters. Let’s start by giving a k of 3.
First the centroids are placed randomly and the distance from each point to each centroid is calculated. Points are then assigned to the cluster that corresponds to the nearest centroid: if a point is closest to centroid 1, it is placed into cluster 1.
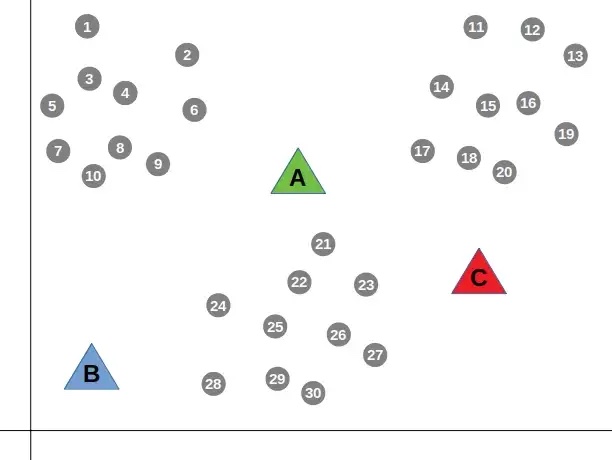
Next, the mean distance from all points belonging to a cluster to that cluser’s centroid is calculated.
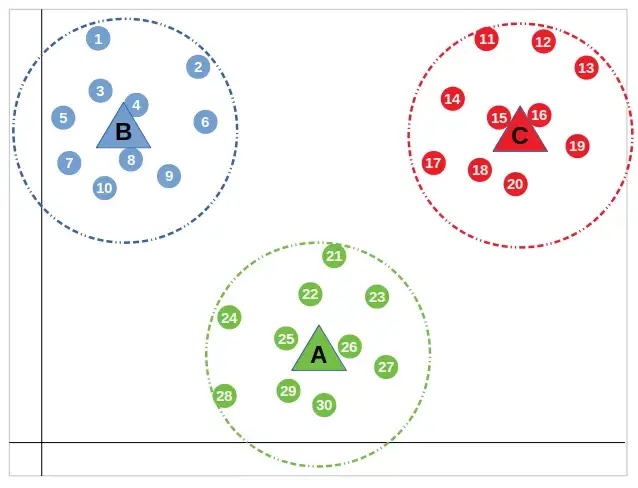
Then, the “centroids” are moved to that mean value that was calculated and the process of assigning points and finding the mean value is repeated.
This is done until the distance between the centroid and the nearest points doesn’t change. All points that are closest to the centroid are placed in that cluster
Let’s try clustering on our own example:
theme_set(theme_classic(base_size = 10))
test_data <- data.frame("x_val" = c(1, 3, 10, 12, 11,
13, 11, 3, 2, 15,
9, 2, 13, 12, 11),
"y_val" = c(10, 12, 3, 2, 10,
3, 1, 10, 13, 2,
1, 13, 12, 13, 11))
rownames(test_data) <- letters[1:nrow(test_data)]Let’s quickly plot it to get a feeling of what it looks like
ggplot(test_data, aes(x = x_val, y = y_val)) +
ggplot2::geom_point(size = 2)
Here it looks like we have three clusters. Let’s try running the k means clustering algorithm. We will be using kmeans. The centers corresponds to the number of clusters we expect in the data. The nstart corresponds to the number of random starting points to try (like the randomly placed centroids above).
The return of this function is a list. To figure out the components returned we can use names()
names(km.res)[1] "cluster" "centers" "totss" "withinss"
[5] "tot.withinss" "betweenss" "size" "iter"
[9] "ifault" The actually cluster information is in km.res$cluster, the position of the centroids is in km.res$centers
km.res$clustera b c d e f g h i j k l m n o
1 1 3 3 2 3 3 1 1 3 3 1 2 2 2 km.res$centers x_val y_val
1 2.20000 11.6
2 11.75000 11.5
3 11.66667 2.0Let’s add our clustering information to our data frame
cluster_k3 <- cbind(test_data, "cluster" = km.res$cluster)And replot with the new clusters
cluster_k3$cluster <- factor(cluster_k3$cluster)
ggplot(cluster_k3, aes(x = x_val, y = y_val, color = cluster)) +
ggplot2::geom_point(size = 2)
This looks like it did a pretty good job! What if we repeat with different values for k?
- K = 2
set.seed(123)
km.res2 <- kmeans(test_data, centers = 2, nstart = 25)
cluster_k2 <- cbind(test_data, "cluster" = km.res2$cluster)
cluster_k2$cluster <- factor(cluster_k2$cluster)
ggplot(cluster_k2, aes(x = x_val, y = y_val, color = cluster)) +
geom_point(size = 2)
Now two populations that appear visually different have been clumped together because we allowed for only 2 centroids.
Exercise Repeat the process above, but compute for 4 clusters
# TODO find k = 4 clustersNote, the nstart value and the set seed is very important. If we don’t set a seed and only do one start, we end up with very different results when running several times:
km.res <- kmeans(test_data, centers = 3, nstart = 1)
cluster_k3 <- cbind(test_data, "cluster" = km.res$cluster)
cluster_k3$cluster <- factor(cluster_k3$cluster)
ggplot(cluster_k3, aes(x = x_val, y = y_val, color = cluster)) +
ggplot2::geom_point(size = 2)
km.res <- kmeans(test_data, centers = 3, nstart = 1)
cluster_k3 <- cbind(test_data, "cluster" = km.res$cluster)
cluster_k3$cluster <- factor(cluster_k3$cluster)
ggplot(cluster_k3, aes(x = x_val, y = y_val, color = cluster)) +
ggplot2::geom_point(size = 2)
km.res <- kmeans(test_data, centers = 3, nstart = 1)
cluster_k3 <- cbind(test_data, "cluster" = km.res$cluster)
cluster_k3$cluster <- factor(cluster_k3$cluster)
ggplot(cluster_k3, aes(x = x_val, y = y_val, color = cluster)) +
ggplot2::geom_point(size = 2)
km.res <- kmeans(test_data, centers = 3, nstart = 1)
cluster_k3 <- cbind(test_data, "cluster" = km.res$cluster)
cluster_k3$cluster <- factor(cluster_k3$cluster)
ggplot(cluster_k3, aes(x = x_val, y = y_val, color = cluster)) +
ggplot2::geom_point(size = 2)
Hierarchical clustering
Another option for clustering is using hierarchical clustering. This is another popular method and results in a dendrogram which you’ve likely seen before.
I’m loosely following the tutorial here through this section. Click on the above link for a more in-depth discussion.
Basically, hierarchical clustering starts by treating each sample as a “cluster”. It then does the following steps
- Identify the two clusters that are closest together
- Merge these two clusters to form a new cluster
Steps 1 and two are repeated until only one large cluster remains
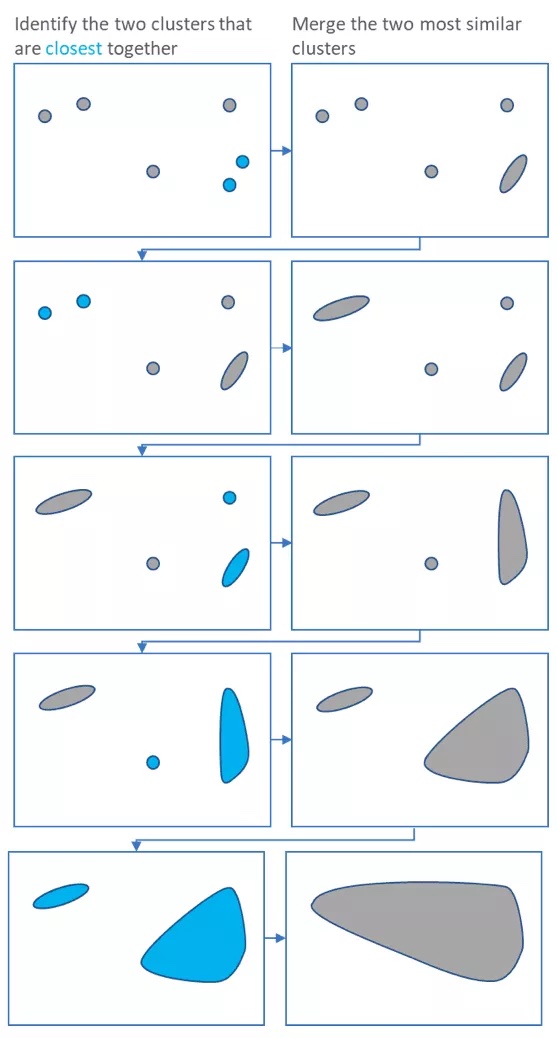
Each merging step is used to build a dendrogram
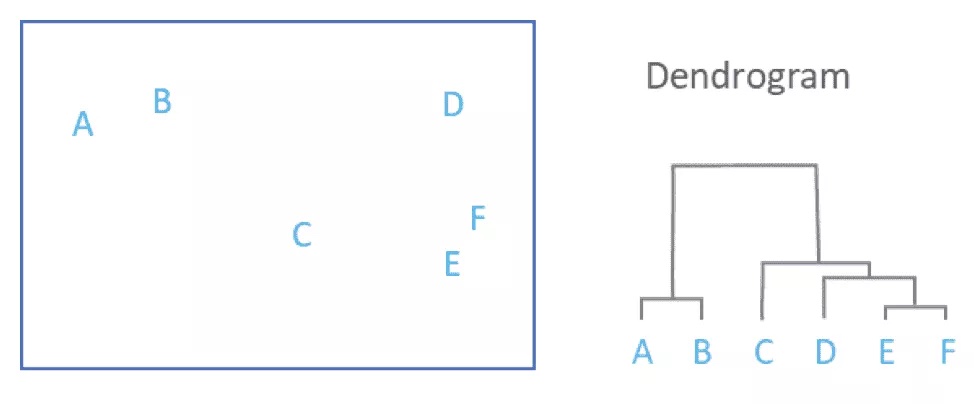
To get an idea of how this is working, we can use the same toy data we generated above
test_data <- data.frame("x_val" = c(1, 3, 10, 12, 11,
13, 11, 3, 2, 15,
9, 2, 13, 12, 11),
"y_val" = c(10, 12, 3, 2, 10,
3, 1, 10, 13, 2,
1, 13, 12, 13, 11))
rownames(test_data) <- letters[1:nrow(test_data)]
test_data %>%
dplyr::mutate(sample = rownames(.)) %>%
ggplot(aes(x = x_val, y = y_val, label = sample)) +
geom_point(size = 2) +
geom_text(hjust=2, vjust=0)
First, we should find the distances between the points. Below is the eucledian distances. Notice that the distance is computed for the rows. If we wanted to compute distances for the columns we would need to transform the matrix using t()
dist(test_data[1:5,]) a b c d
b 2.828427
c 11.401754 11.401754
d 13.601471 13.453624 2.236068
e 10.000000 8.246211 7.071068 8.062258We can now run hclust which will perform hierarchical clustering using the output of dist

Based on the dendrogram above, we can see what points are the most similar (ie were clustered first). We can also see that it makes the most sense to break the data into 3 clusters. We can pull out these clusters using cutree
hc_clusters3 <- cutree(tree = hc, k =3)
hc_clusters3a b c d e f g h i j k l m n o
1 1 2 2 3 2 2 1 1 2 2 1 3 3 3 hc_clusters3 <- cbind(test_data, "cluster" = hc_clusters3)
hc_clusters3$cluster <- factor(hc_clusters3$cluster)
hc_clusters3 %>%
dplyr::mutate(sample = rownames(.)) %>%
ggplot(aes(x = x_val, y = y_val, label = sample, color = cluster)) +
geom_point(size = 2) +
geom_text(hjust=2, vjust=0)
And now you can see that the clusters agree exactly with the k - means clusters
Exercise Repeat finding clusters using different points on the tree. For example, what if you make 2 clusters? What if you make 4 or 5?
# TODO repeat finding clusters with different numbers of clustersQuestion Are the clusters always the same as the k-means clusters? Do they ever differ?
Using dimensionality reduction to visualize data
In the example above, we only had two dimensions and could easily visualize them. What about our example dataset with 50 names and 20 states? How do we visualize that type of data? Even more daunting,what if we have 20,000 genes and 18 samples as part of a RNA-seq experiment, or even worse, 20,000 genes and 30,000 cells as part of a single cell RNA-seq experiment? To visualize this data, we have to use something called dimensionality reduction. PCA is a common dimensionality reduction to use and will work well for lots of data type (like bulk RNA-seq). Other dimensionality reduction tools will need to be used (like UMAP) to visualize single cell RNA-seq and CYTOF datasets (and other single cell approaches).
Visualizing the data with PCA
There is an amazing tutorial on how PCA works here. We will talk a little today about how PCA works, but I highly recommend looking at this book for PCA and to learn many of the important statistical techniques used regularly in computational biology. One thing I like about the book is it includes a lot of R code that you can run yourself so you can really understand how these techniques work.
The overall goal of PCA is to find linear models that best fit the data.
Let’s walk through PCA (following the tutorial in Modern Statistics for Modern Biology) with only Alabama and Colorado to see how it works.
names_mat <- read.csv(here("class_8-10_data", "boy_name_counts.csv"),
row.names = 1) %>%
as.matrix()
normalized_mat <- t(t(names_mat) / colSums(names_mat))
# Selecting just Alabama and Colorado, making a data frame for plotting
normalized_dat <- normalized_mat %>%
data.frame %>%
dplyr::select(Alabama, Colorado)The first way we can think about going from 2 dimensions to 1 dimension is to simply just use the values from one of the dimensions. For example, if we have Alabama and Colorado, we can simply describe the data using only the values for Alabama. This idea is shown as the red points below
dim_plot <- ggplot(normalized_dat, aes(x = Alabama, y = Colorado)) +
geom_point(size = 2)
dim_plot + geom_point(aes(y = 0), colour = "red") +
geom_segment(aes(xend = Alabama, yend = 0), linetype = "dashed")
Unfortunately, this loses all of the information from Colorado. Instead, we can also try to find a line of best fit using linear regression. Linear regression is done using a model with response and explanatory variables. A line is fit to the data that attempts to minimize the distance from the response variables to the line. Because there is always a response and explanatory variable, we can perform linear regression to minimize the distance for Colorado or Alabama.
Let’s first minimize the distance for Colorado. To perform linear regression, we will use the lm function. If we want to minimize the distance to Colorado, Colorado will be the response variable and our model will be Colorado ~ Alabama
[1] "coefficients" "residuals" "effects" "rank"
[5] "fitted.values" "assign" "qr" "df.residual"
[9] "xlevels" "call" "terms" "model" After running lm the return value is a list. The coefficients will give us the slope and the intercept (think \(y = ax + b\) ). We can also use the fitted.values which are the predicted values for Colorado based on the model.
a1 <- reg1$coefficients[1] # intercept
b1 <- reg1$coefficients[2] # slope
pline1 <- dim_plot + geom_abline(intercept = a1, slope = b1,
col = "blue")
pline1 + geom_segment(aes(xend = Alabama, yend = reg1$fitted.values),
colour = "red", arrow = arrow(length = unit(0.15, "cm")))
We can find the variance of the points on the blue line by using Pythagoras’ theorem (because the values have x and y coordinates).
We can now repeat linear regression and now minimize the distance for Alabama to the regression line (now Alabama is the response variable).
reg2 <- lm(Alabama ~ Colorado, data = normalized_dat)
a2 <- reg2$coefficients[1] # intercept
b2 <- reg2$coefficients[2] # slope
pline2 <- dim_plot + geom_abline(intercept = -a2/b2, slope = 1/b2,
col = "darkgreen")
pline2 + geom_segment(aes(xend=reg2$fitted.values, yend=Colorado),
colour = "orange", arrow = arrow(length = unit(0.15, "cm")))
We can also find the variance of the points that are fit to this regression line
So far we have attempted to minimize either the distance of Alabama or Colorado values from the regression line. Instead of minimizing just one distance, PCA tries to minimize the total distance from the line (in both the X and Y directions).
Let’s run PCA and use matrix multiplication to visualize the first PC in our x-y space
svda <- svd(as.matrix(normalized_dat))
pc <- as.matrix(normalized_dat) %*% svda$v[, 1] %*% t(svda$v[, 1]) # Matrix multiplication
bp <- svda$v[2, 1] / svda$v[1, 1]
ap <- mean(pc[, 2]) - bp * mean(pc[, 1])
dim_plot + geom_segment(xend = pc[, 1], yend = pc[, 2]) +
geom_abline(intercept = ap, slope = bp, col = "purple", lwd = 1.5)
We can now find the variacne of the points in the PC space
Notice that this variance is the largest of the three lines we have fit.
From Modern Stats for Modern Biology
If we are minimizing in both horizontal and vertical directions we are in fact minimizing the orthogonal projections onto the line from each point.
The total variability of the points is measured by the sum of squares ofthe projection of the points onto the center of gravity, which is the origin (0,0) if the data are centered. This is called the total variance or the inertia of the point cloud. This inertia can be decomposed into the sum of the squares of the projections onto the line plus the variances along that line. For a fixed variance, minimizing the projection distances also maximizes the variance along that line. Often we define the first principal component as the line with maximum variance.
Although it’s good to know the inner workings of PCA, we can simply run this PCA analysis using prcomp.
Now that we have learned about some of the clustering techniques, we are going to continue working with the same data we used to talk about matrices, the top 100 boy and girl names by state for 2020. We will want to use the normalized data for these examples.
names.pca <- prcomp(normalized_mat)The values for the dimensionality reduction are found in the x slot.
pca_vals <- names.pca$x %>%
data.frame()
pca_vals[1:4, 1:4] PC1 PC2 PC3 PC4
William -0.047369020 0.0205532201 -0.03357595 -0.01476594
James -0.039425249 0.0051117061 -0.02086795 -0.01309033
John 0.008912962 -0.0008331344 -0.03046000 -0.01522468
Elijah -0.052513118 -0.0058489913 -0.02466740 0.01209649We can also find the percent of variance explained by each component using the sdev slot
names.pca$sdev[1:5][1] 0.036137672 0.016696954 0.013635319 0.008543108 0.005674905percentVar <- names.pca$sdev^2 / sum( names.pca$sdev^2 )Now we can combine the two to make a PCA plot
ggplot(pca_vals, aes(x = PC1, y = PC2)) +
geom_point(size = 2) +
xlab(paste0("PC1: ",round(percentVar[1] * 100),"% variance")) +
ylab(paste0("PC2: ",round(percentVar[2] * 100),"% variance"))
Implementing clustering on our dataset
Now that we’ve learned how to visualize our data, we will be able to more easily see the clustering results. Let’s put together everything we’ve learned so far and try out the different clustering methods on our names data.
K means clustering of names
The first thing we need to do is decide if we want to cluster the states or the names. Our first question is what names have the most similar usage? To answer this question, we will need to cluster the names.
From the PCA plot above, it doesn’t look like there are strong clusters. Let’s start with 2 clusters.
William James John Elijah Noah Liam Mason
2 2 1 2 3 3 1
Oliver Henry Jackson Samuel Jaxon Asher Grayson
2 2 1 1 1 1 1
Levi Michael Carter Benjamin Charles Wyatt Thomas
1 1 1 2 1 1 1
Aiden Luke David Owen Daniel Logan Joseph
1 1 1 1 1 1 1
Lucas Joshua Jack Alexander Maverick Gabriel Ethan
1 1 1 1 1 1 1
Eli Isaac Hunter Ezra Theodore
1 1 1 1 1 We can again add this information to the plot
pca_cluster <- cbind(pca_vals, "cluster" = km.res2$cluster)
pca_cluster$cluster <- factor(pca_cluster$cluster)
ggplot(pca_cluster, aes(x = PC1, y = PC2, color = cluster)) +
geom_point(size = 2) +
xlab(paste0("PC1: ",round(percentVar[1] * 100),"% variance")) +
ylab(paste0("PC2: ",round(percentVar[2] * 100),"% variance"))
Let’s try again with 3 clusters
set.seed(123)
km.res3 <- kmeans(normalized_mat, centers = 2, nstart = 25)
pca_cluster <- cbind(pca_vals, "cluster" = km.res3$cluster)
pca_cluster$cluster <- factor(pca_cluster$cluster)
ggplot(pca_cluster, aes(x = PC1, y = PC2, color = cluster)) +
geom_point(size = 2) +
xlab(paste0("PC1: ",round(percentVar[1] * 100),"% variance")) +
ylab(paste0("PC2: ",round(percentVar[2] * 100),"% variance"))
Exercise Try with 4 clusters, what names cluster together?
# TODO Repeat with 4 clusters and repeat what names cluster togetherHierarchical clustering of names
Now let’s repeat the clustering of names using hierarchical clustering

Based on the above plot, it seems like 3 clusters might be a good starting point
hc_clusters3 <- cutree(tree = hc, k =3)
hc_clusters3 <- cbind(pca_vals, "cluster" = hc_clusters3)
hc_clusters3$cluster <- factor(hc_clusters3$cluster)
ggplot(hc_clusters3, aes(x = PC1, y = PC2, color = cluster)) +
geom_point(size = 2) +
xlab(paste0("PC1: ",round(percentVar[1] * 100),"% variance")) +
ylab(paste0("PC2: ",round(percentVar[2] * 100),"% variance"))
Exercise What two values are their own cluster? Hint either remake the plot with the points labeled or look at the dendrogram above.
Repeating by clustering states
What if our question is what states have the most similar name usage? We will answer this by instead clustering on the states.
Again we will start by making a PCA plot. This time we will need to transform the matrix first before running PCA to run it on the sates instead
We can again pull out the values for the PCA from the x slot and the percent of the variance explained by each PC by using the sdev slot.
pca_vals <- states_pca$x %>%
data.frame()
percentVar <- states_pca$sdev^2 / sum( states_pca$sdev^2 )Now we can combine the two to make a PCA plot
ggplot(pca_vals, aes(x = PC1, y = PC2)) +
geom_point(size = 2) +
xlab(paste0("PC1: ",round(percentVar[1] * 100),"% variance")) +
ylab(paste0("PC2: ",round(percentVar[2] * 100),"% variance"))
We can now start by looking at 3 clusters using the kmeans clustering algorithm. Again, we will need to first transform the data to cluster the states rather than the names
Alabama Alaska Arizona Arkansas California
1 2 3 1 3
Colorado Connecticut Delaware Florida Georgia
2 3 3 3 1
Hawaii Idaho Illinois Indiana Iowa
3 2 3 2 2
Kansas Kentucky Louisiana Maine Maryland
2 1 1 2 3 Notice now we are clustering by the state instead of the names.
pca_cluster <- cbind(pca_vals, "cluster" = km.res3$cluster)
pca_cluster$cluster <- factor(pca_cluster$cluster)
ggplot(pca_cluster, aes(x = PC1, y = PC2, color = cluster)) +
geom_point(size = 2) +
xlab(paste0("PC1: ",round(percentVar[1] * 100),"% variance")) +
ylab(paste0("PC2: ",round(percentVar[2] * 100),"% variance"))
This seems to pretty nicely segregate our data.
Hierarchical clustering of states
Now let’s repeat the clustering of names using hierarchical clustering, again we will need to transform the data first.

In the plot above we see 3 clear clusters
hc_clusters3 <- cutree(tree = hc, k =4)
hc_clusters3 <- cbind(pca_vals, "cluster" = hc_clusters3)
hc_clusters3$cluster <- factor(hc_clusters3$cluster)
ggplot(hc_clusters3, aes(x = PC1, y = PC3, color = cluster)) +
geom_point(size = 2) +
xlab(paste0("PC1: ",round(percentVar[1] * 100),"% variance")) +
ylab(paste0("PC3: ",round(percentVar[3] * 100),"% variance"))
Exercise
Try out several different cluster numbers for both the kmeans clustering and the hierarchical clustering. Do you ever find cases where they differ? What if you try different numbers of starts for kmeans?
# TODO test out several hierarchical and k means clustering cluster numbersI’m a biologist, why should I care?
- Clustering and visualizations are important for any question you are answering
- Clustering and dimensionality reduction are key aspects of single cell RNA-seq analysis
- CYTOF also relies on clustering and dimensionality reduction techniques
- Even a project where you’ve taken several measurements (that you expect to be related) can be used to cluster your samples
- Phylogenetic trees are just a form of hierarchical clustering
- You will likely encounter clustering in papers that you read. My goal is to improve your understanding of the techniques so you can better interpret them on your own
Acknowldgements and additional references
The content of this class borrows heavily from previous tutorials:
- K- means clustering
- Hierarchical clustering
- PCAs